BAM: Bottleneck Attention Module 리뷰
Abstract
- 본 논문에서는 Deep neural network에서 Attention의 효과에 중점을 둔다.
- 모든 feed forward convolution 신경망과 통합할 수 있는 BAM(Bottleneck Attention Module)을 제시.
- BAM은 channel과 spatial 두 가지 별도의 경로를 따라 Attention map을 추론.
- BAM은 feature map의 다운샘플링이 발생하는 모델의 각 병목 지점(bottleneck)에 배치.
- end-to-end 방식으로 학습할 수 있다.
Introduction
- 딥러닝은 분류, 감지, 분할 및 제어 문제를 포함한 일련의 패턴 인식을 위한 강력한 도구였다.
- optimizer 설계, 적대적 훈련 방식, 탐지를 위한 2단계 아키텍처등과 같은 작업별로 다양한 방법으로 성능을 향상시켜왔다.
- 이 중 성능을 향상시키는 근본적인 접근 방식은 좋은 backbone 아키텍처를 설계하는 것.
- 본 논문에서 Attention의 효과를 조사하고 간단하고 가벼운 모듈을 제안.
주요 기여 세 가지
- 부가 기능 없이 모든 CNN과 통합될 수 있는 간단하고 효과적인 Attention module BAM을 제안.
- BAM의 설계를 검증
- 여러 벤치마크(CIFAR-100, ImageNet-1K, VOC 2007등)에서 BAM의 효율성을 검증.

Related Work
많은 연구에서 Attention은 인간의 인식에 중요한 역할을 한다는 것을 보여준다. (인간 눈의 중심의 해상도는 주변 영역보다 높음)
Cross-modal attention
- Attention 메커니즘은 다중 모달 성정에서 널리 사용되는 기술이다. 특히 특정 모달리티가 다른 모달리티에 의존하여 처리되어야 하는 경우에 효과적.
- 특히, VQA(Visual question answering)와 같은 작업에서 질문에 따른 이미지의 특정 부분을 효과적으로 추출.
- Attnetion 메커니즘은 이미지 특징에서 질문에 관련된 측면을 부드럽게 선택하는 역할을 한다.
Self-attention
- DNN에 Attention 메커니즘을 통합하는 다양한 접근 방식이 존재.
- 특징 추출과 Attention 생성을 end-to-end 방식으로 공동 훈련하는 방식으로 DNN에 Attention을 통합.
- 예로 hourglass 모듈을 사용한 Residual Attention Networks, ‘Squeeze-and-Excitation’ 모듈을 제안한 논문을 언급.
Adaptive modules
- 이전 여러 연구에서 입력에 따라 출력을 동적으로 변경하는 적응형 모듈을 사용.
- Dynamic Filter Network, Spatial Tansformer Network, Deformable Convolutional Network를 예시로 언급.
- BAM은 위 접근 방식과 유사하게 Attention 메커니즘을 통해 feature map을 동적으로 억제하거나 강조하는 적응형 모듈이라고 할 수 있다.
Bottleneck Attention Module

BAM은 입력 feature map F에 대해 3D Attention map M(F)를 추론한다.

향상된 feature map F'는 위과 같이 계산된다. (여기서 ⊗는 element-wise multiplication, 요소곱)
gradient 흐름의 용이를 위해 Attention 메커니즘과 함께 residual learning 방식을 사용.
효율적이면서 강력한 모듈을 설계하기 위해, 두 개의 별도 분기에서 Channel Attention Mc(F)와 Spatial Attention Ms(F)를 계산한 다음 .Attention map M(F)를 다음과 같이 계산한다.

두 분기의 출력은 덧셈 전에 R^(CxHxW)로 resizing. (여기서 σ\sigma는 시그모이드 함수)
Channel attention branch

- 각 채널에는 특정 feature 응답이 포함되어 있으므로 채널 branch에서 채널 간 관계를 활용한다.
- 각 채널의 feature map을 집계하기 위해 feature map F에 대해 Global Average Pooling을 수행, Fc를 생성.
- Fc에서 채널 간 attention을 추정하기 위해 하나의 은닉층을 가진 MLP를 사용. (은닉층의 크기는 오버헤드를 절약하기 위해 C/r x 1 x 1로 설정, r은 감소 비율)
- MLP 후에 Batch Normalization 레이어를 추가하여 scale을 조정.

Spatial attention branch
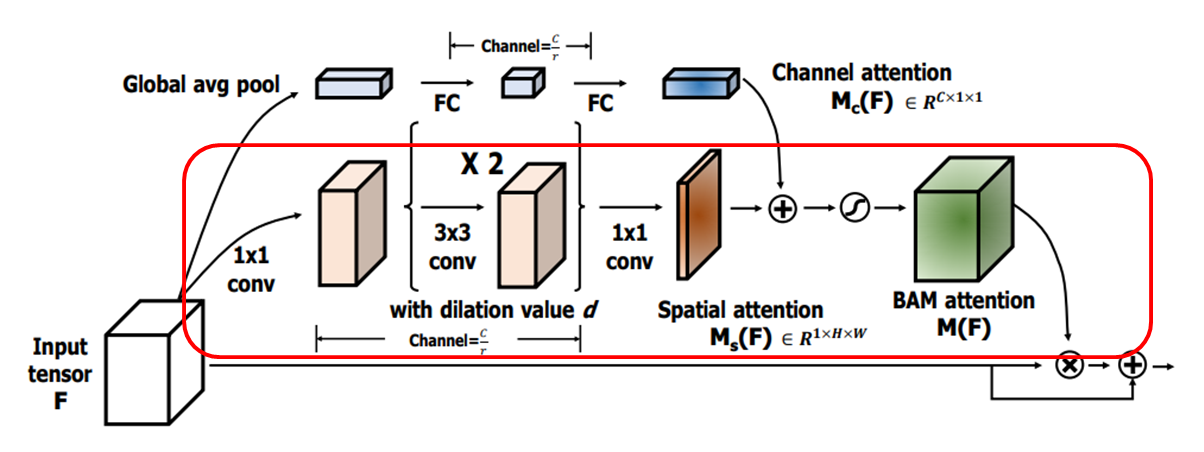
- Spatial branch는 서로 다른 공간 위치의 feature를 강조, 억제하기 위해 spatial attention map Ms(f)를 생성한다.
- 어떤 공간적 위치에 초점을 맞춰야 하는지를 알기 위해서는 contextual(상황별) 정보를 활요하는 것이 중요하다.
- contextual 정보를 효과적으로 활용하려면 넓은 receptive filed를 확보하는 것이 중요.
- 본 논문은 넓은 receptive filed를 효율적으로 확대하기 위해 dilated convolution를 활용.

Combine two attention branches
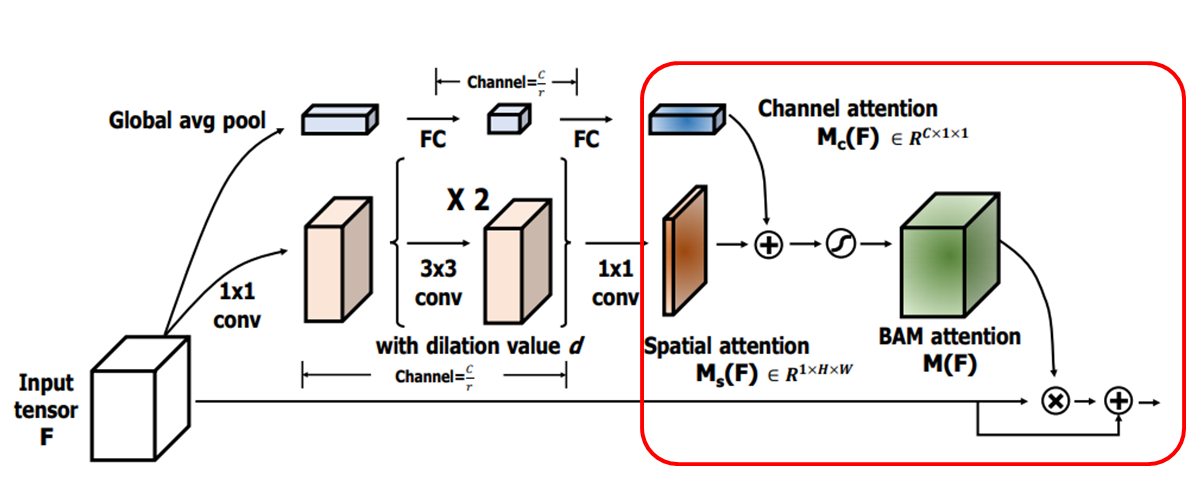
- 두 가지 Attention branch에서 Mc(F)와 Ms(F)를 획득한 후 이를 결합하여 최종 3D Attention Map M(F)를 생성.
- 결합전 Attention Map을 R^(CxHxW)로 확장.
- 효율적인 gradient flow를 위해 요소별 합산, 곱셈, 최대 연산 중에서 요소별 합산을 선택. (element-wise summation)
- 합산 후 시그모이드 함수를 사용해서 0~1 범위에서 최종 3D Attention Map M(F)를 얻는다.
- 이 3D Attention Map은 입력 feature map F와 요소별 곱셈을 수행한 다음, 원래의 입력 feature map에 더하여 향상된 feature map F′을 얻습니다.

Conclusion
- 본 논문에서는 network의 표현력을 향상시키는 새로운 접근 방식인 BAM을 제시.
- BAM은 두 개의 별도 경로를 통해 효율적으로 집중하거나 억제할 대상과 위치를 학습하고 개선.
- CIFAR-100, ImageNet-1K, VOC2007 및 MS COCO의 벤치마크 데이터 세트에서 모든 기준을 능가하는것을 확인.