Dilated Convolution?


Dilated Convolution은 위와 같이 필터 내부에 zero padding을 추가하여 강제로 receptive field를 늘려주는 convolution이다.
Dilated Convolution, 왜 사용할까? (Receptive field)
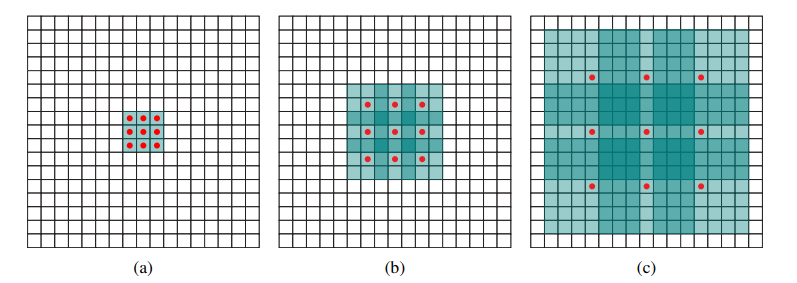
convolution을 할 때 필터가 수용하는 영역(receptive field)이 넓을수록 이미지의 전체적인 특징, 문맥적(context)인 특징을 잡아내기 수월한데, 그렇다고 필터의 크기를 넓히게 되면 그만큼 가중치가 늘게 되고 overfitting이 발생할 수 있다.
Dilated Convolution은 receptive field는 넓혀주면서 파라미터 개수는 유지시켜주는 장점이 있다.
i-dilated convolution receptive filed size = F(i+1) = (2^(i+2) - 1) x (2^(i+2) - 1)
ex) (b) F2 = (2^3 - 1) x (2^3 - 1) = 7 x 7
Dilated convolution의 활용
Dilated convolution을 소개하는 논문에서는 dilated convolution의 활용으로 Context Module과 Front-end Module을 소개한다. 이 두 가지를 간단하게 살펴보자. (사실 간단하지가 않다...ㅠ)
Context Module
Context Module은 다중 scale의 contextual 정보를 추출하는 dense prediction의 성능을 향상할 수 있게 설계된 모듈이다.
(dense prediction : 픽셀 단위 예측, 단순하게 segmentation network라고 생각하면 될 것 같다.)
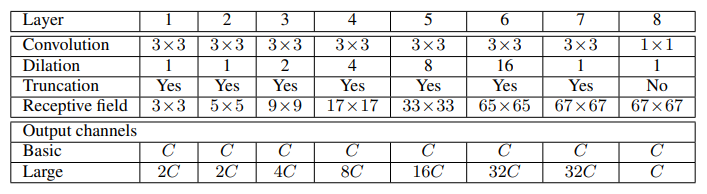
- Module은 C개의 feature map을 입력으로 받고 C개의 feature map을 출력으로 생성한다.
- 입력과 출력이 동일한 형태를 가지기 때문에 기존 dense prediction 구조에 연결되어 사용할 수 있다.
- Module은 Basic form, Large form이 있는데 논문에서는 Basic form을 중점적으로 다룬다.
- Context Module은 Dilation Factor(1, 1, 2, 4, 8, 16, 1)와 3 x 3 convolution을 적용하는 7개의 Layer가 있다.
- 최종 Layer에서는 1 x 1 x C convolution을 수행하고 출력을 생성한다.
convolution network는 일반적으로 random 분포의 샘플을 사용하여 초기화하는데, 이러한 방식은 context module에 효과적이지 않았다. 그래서 논문 실험에서 찾은 대체 방식이 아래식이다.
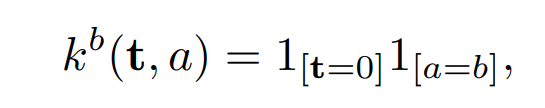
- a는 입력의 feature map이고, b는 출력 맵의 index이다.
- 이 식은 최근 recurrent network(RNN)에서 사용되는 초기화 형태이다.
- 이 초기화 방법은 Backpropagation과정에서 정보를 전달하는 동작을 크게 개선할 수 없다고 하는데.
- 그러나 실험 결과 그렇지 않고, Backpropagation과정에서 contextual 정보를 안정적으로 수집하여 정확도를 높였다.
논문에서는 Basic Module 만으로도 양적, 질적으로 dense prediction 정확도를 높일 수 있다는 것을 확인했다고 한다.
Front-End Module
Front-end module은 VGG-16 network를 변형하여 만든 모듈이다.

- FCN에서는 VGG-16 network의 뒷단을 그대로 사용했지만, Front-end module은 뒤 2개의 pooling layer를 제거하고 따라오는 convolution layer를 dilated convolution으로 대체하였다.
- FCN에서는 pooling layer를 거쳐 feature map의 크기가 원영상의 1/32로 작아져 이를 upsampling, skip combining으로 해결.
- Fron-end module은 pooling layer를 제거하기 때문에 feature map의 크기가 1/8 수준 가지만 작아져, FCN보다 detail 한 정보가 살아있게 된다.
- 또한 FCN 보다 upsampling, skip combining 연산이 줄어들어 더 간단해지면서 정확해지는 효과를 얻음.
끝.
'DeepLearning > Concept' 카테고리의 다른 글
| 1x1 Convolution Layer (0) | 2021.08.17 |
|---|---|
| Dropout (0) | 2021.07.16 |
| mAP(mean Average Precision) (0) | 2021.01.06 |
| Back Propagation, 역전파 (0) | 2021.01.05 |
| CNN, Convolutional Neural Network, 합성곱 신경망 (0) | 2021.01.04 |