반응형
1. Abstract
- 본 논문에서는 간단한 Single approach로 시각적 object tracking과 semi-supervised video object segmentation을 실시간으로 수행하는 방법을 설명한다.
- SiamMask라고 불리는 방법은 binary segmentation task로 object tracking을 위한 fully-convolutional Siamese approaches의 오프라인 훈련 절차를 개선한다.
2. Introduction
- Video의 첫 번째 프레임에서 임의의 관심 대상의 위치가 주어지면 시각적 Object Tracking의 목적은 모든 후속 프레임에서 가능한 최고의 정확도로 해당 위치를 추정하는 것이다.
- Video가 streaming 되는 동안 online으로 tracking을 수행할 수 있는 것이 중요.

- 기존의 VOS(Video Object Segmenation) 방법은 픽셀 수준의 추정을 하기 때문에 bounding box보다 오래 걸린다. → 실시간에 적합하지 않음.
- 본 논문에서 SiamMask를 제안하여 임의의 Object Tracking과 VOS간의 격차를 줄이는 것을 목표로 한다.
- 세 가지 작업에 대해 Siam network를 동시에 training한다.
- Sliding window 방식으로 대상 객체와 여러 후보 사이의 유사도 측정을 학습. → dense response map.
- RPN을 통한 Bounding box 회귀.
- Binary segmentation → object인지 아닌지 나타내는 이진 분할.
- 일단 훈련되면, SiamMask는 single bounding box 초기화에만 의존하며 업데이트 없이 online으로 초당 55프레임으로 작동한다.
3. Methodology
Online 운용성과 빠른 속도를 위해 fully-convolutional Siamese framework 채택.
3.1. Fully-convolutional Siamese networks
SiamFC

- Tracking system의 기본 구성 요소로, 검색 image-x와 예제 image-z를 비교하여 dense response map을 얻는 오프라인 fully-convolutional Siamese network를 사용할 것을 제안.

- 두 입력 z, x는 동일한 CNN \(fθ\)에 의해 처리되며, 상호 상관(cross-correlated) 된 두 가지 feature map을 생성.
- x → 대상의 마지막 추정 위치를 중심으로 하는 더 큰 crop.
- z → 대상 object를 중심으로 하는 w x h crop.
- 이 논문에서는 response map(RoW)(위 식의 왼쪽)의 각 공간 요소를 참조한다.
- Row → Response of a candidate Window
- 예를 들어 \(g^nθ\)(z, x)는 예제 z와 x의 n번째 후보 window 사이의 유사성을 인코딩한다.
- SiamFC의 경우 목표는 검색 영역 x의 대상 위치에 해당하는 response map의 최대값이다.
- SiamFC는 \(L_{sim}\)이라고 하는 Logistic loss를 통해 훈련 됨.
SiamRPN

- SiamRPN에서 각 행은 k개의 anchor box 제안과 해당 object/background 점수를 인코딩한다.
- SiamRPN은 분류 점수와 병렬로 Bounding Box 예측을 출력.
- 두 출력 branch는 smooth L1, cross-entropy loss를 사용하여 훈련 된다. (각각 \(L_{box}\), \(L_{score}\) )
3.2. SiamMask

- 유사성 score와 bounding box 좌표 외에도 fully-convolutional Siamese network의 RoW가 픽셀 단위 binary mask를 생성하는데 필요한 정보를 인코딩하는 것이 가능하다는 것을 보여준다.
- → classification, detection 말고도 Siamese network를 사용해서 segmentation을 할 수 있다는 것을 보여준다.
- 이는 기존 Siamese tracker를 추가 분기 및 손실로 확장함으로써 달성 가능하다.
- 학습 가능한 parameter φ가 있는 간단한 two-layer 신경망 \(h_φ\)를 사용하여 w x h binary mask(각 RoW 대해)를 예측한다.

- \(m_n\) → n번째 RoW에 해당하는 mask 예측이라 하고, mask 예측이 \(x\)를 분할하는 이미지와 \(z\)에 있는 대상 object 객체의 함수임을 알 수 있다.
Loss function

- Traning 중에 각 RoW는 gound-truth binary label인 \(y_n\in\{\pm1\}\) 로 레이블이 지정되고, \(w \times h\)크기의 픽셀 별 ground-truth mask인 \(c_n\)과도 연결된다.
- \(c^{ij}_n\in\{\pm1\}\) → n번째 후보 RoW에서 Object mask의 픽셀 \((i, j)\)에 해당하는 label을 나타낸다.
- mask prediction task에 대한 손실 함수 \(L_{mask}\)는 모든 RoW에 대한 binary logistic regression loss(이진 로지스틱 회귀 손실)이다.
Mask representation
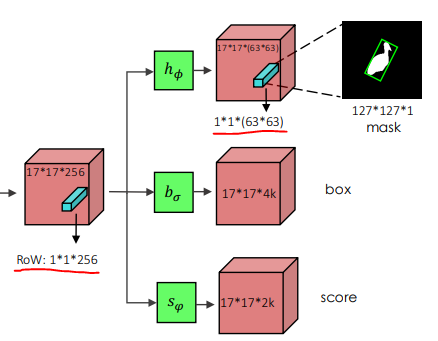
- SiamMask에서 Mask represetation는 \(f\theta(z)\)와 \(f\theta(x)\) 사이의 depth-wise cross-correlation에 의해 생성된 (17 x 17) RoWs중 하나에 해당.
- 중요한 것은, segmentation task인 network \(h_φ\)는 두 개의 1x1 convolution layer로 구성 되는데, 하나는 \(256\)개이고 다른 하나는 \(63^2\)개 채널이다.

- 이를 통해 픽셀 분류기는 전체 RoW에 포함된 정보를 활용할 수 있으므로 위 그림처럼 유사한 instance 간에 모호함을 해소하는데 중요한 x의 후보 Window를 완전히 볼 수 있다.
Two variants
- SiamFC 및 SiamRPN의 구조를 Segmentation 및 Loss \(L_{mask}\)로 확장하여 SiamMask의 two-branch, three-branch를 얻는다.
- 이들은 각각 다음과 같이 정의된 multi-task loss \(L_{2B}, L_{3B}\)를 최적화 한다.
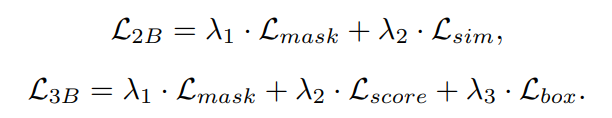
- \(L_{3B}\)의 경우 anchor box중 하나가 최소 0.6의 gound-truth box와 함께 IoU를 가지면 RoW는 양의 값으로 간주되고(\(y_n = 1\)), 그렇지 않으면 음수 값으로(\(y_n = -1\)) 간주된다.
- \(L_{2B}\)의 경우 “Fully-convolutional siamese networks for object tracking” 논문과 동일한 방법으로 양의 샘플과 음의 샘플을 정의.
- 위 식에서 하이퍼 파라미터는 λ1 = 32, λ2 = λ3 = 1 로 설정.
Box generation

- binary mask에서 bounding box를 생성하기 위해 세 가지 다른 전략을 고려한다.
- axis-aligned bounding rectangle (Min-max)
- rotated minimu bounding rectangle (MBR)
- VOT-2016에서 제안된 automatic bounding box generation (Opt)
3.3. Implementation details
Network architecture
- ResNet-50을 backbone \(f\theta\)로 사용한다.
- deep한 layer에서 높은 공간 해상도(high spatial resolution)을 얻기 위해 stride가 1인 convolution 사용.
- 또한 dilated convolution을 사용하여 receptive field를 증가시킨다.
Training
- SiamFC와 마찬가지로, 각각 127x127 픽셀과 255x255 픽셀의 tempalte 이미지 패치와 검색 이미지 패치를 사용.
- 훈련 중에 무작위로 이미지를 던지고, 검색.
- random translation (up to ±8 pixels), rescaling (of 2 ±1/8 and 2 ±1/4) 방식으로 data augment.
반응형
'DeepLearning > Tracking' 카테고리의 다른 글
| [Tracking] DeepSORT: SIMPLE ONLINE AND REALTIME TRACKING WITH A DEEP ASSOCIATION METRIC 리뷰 (0) | 2026.01.14 |
|---|---|
| [Tracking] SORT: SIMPLE ONLINE AND REALTIME TRACKING 리뷰 (0) | 2025.03.17 |