반응형
Abstract
- 이미지 흐림 제거는 흐릿한 이미지에서 선명한 이미지를 복구하는 것
- CNN은 이 분야에서 좋은 성과를 거두었으나, Transformer라는 대체 네트워크가 더 강력한 성능을 보여주었다
- 본 논문은 Transformer보다 비슷하거나 더 나은 성능을 보여주는 경량 CNN을 제안
- LaKD라는 효율적인 CNN 블록을 제안
- Transformer보다 비슷하거나 더 큰 ERF를 달성하며 파라미터는 더 작다
- 또한 ERF를 정량적으로 특성화하고 간결하고 직관적인 ERFMeter 메트릭을 제안
Introduction
- 기존 알고리즘은 blur kernel 추정과 prior 또는 regularzier(정규화)를 사용한 블라인드 디컨볼루션에 의존
- CNN의 발전에 따라 이미지 디블러링에 사용
- 최근에는 CNN의 제약을 완화하는 구조인 Transformer가 등장하여 장거리 공간 종속성 문제는 해결
- 하지만 Transformer는 계산 복잡도가 높다
- 이 논문에서는 ERF와 대형 kernel 합성곱이 이미지 디블러링에 미치는 영향을 심층적으로 탐구하고 대형 kernel 깊이별 합성곱과 공간 채널 혼합 메커니즘으로 구성된 LaKD라는 블록을 갖춘 순수 CNN 아키텍처를 고안
- 또한 ERFMeter라는 ERF 평가 방법을 제안
Related Work
Image Deblurring
- 기존의 블라인드 blur kernel 추정 디컨볼루션 알고리즘은 반복적 최적화 절차에서 발생하는 오류 전파로 인해 품질과 계산 비용 측면에서 효과적이지 못하다
- 이후 CNN 기반 방법은 end-to-end 솔루션을 제공하고 효율적인 결과를 달성
- Transformer 기반 구조는 디블러링을 포함한 다양한 이미지 복원 작업에서 강력한 성능을 보여주지만 계산 비용이 많이 발생한다
- 이 논문에서는 순수한 CNN 구조를 탐구하여 적은 계산으로 Transformer와 동등하거나 더 나은 성능을 달성
Transformer
- Transformer 아키텍처는 자연어 처리를 위한 모델 구조로 Vision Transformer(ViT)를 도입하여 이미지 데이터에서도 Transformer를 적용할 수 있게 되었다
- local receptive field에 귀납적 편향이 있는 기존 CNN과 달리, self-attention 메커니즘이 있는 Transformer 아키텍처는 주어진 패치의 다른 모든 픽셀과 상호 작용하여 global reciptive field와 long-range feature dependecies를 제공한다
- 그러나 높은 계산 비용으로 인해 고해상도 이미지 데이터에 대한 Transformer의 적용 제한이 있다
Large Kernels
- ViT는 큰 수용 영역을 가지고 있어서 뛰어난 성능을 발휘하는데 이에 따라 연구자들은 전통적인 CNN으로 돌아가 더 큰 kernel을 사용하는 방식을 채택
- RepLKNet과 SLaKNet은 각각 31x31, 51x51 크기의 kernel을 사용하는데 Transformer와 비슷하거나 더 나은 성능을 보인다
- 이미지 복원 작업에서 Large kernel의 영향에 대한 연구는 거의 없으며, 새로운 연구 방향이 제시되고 있다
Methodology
본 논문의 목표는 흐릿한 이미지 I에서 선명한 고해상도 이미지 Y^를 복원하기 위한 효율적인 순수 CNN 모델을 개발하는 것이다
큰 ERF를 얻는 동시에 효율성을 유지하기 위해, self-attention과 대조 적으로 큰 kernel을 사용하여 장거리 픽셀 종속성을 모델링
Overall architecture

- 전체 구조는 U-shape의 계측적 네트워크
- 4단계 대칭 encoder-decoder 모듈로 구성, 각 단계는 N개의 LaKD Block으로 구성되며 N ∈ {N1, N2, N3, N4}
- 입력 이미지 I ∈ R H×W×3 가 주어지면 Convolutional layer를 거쳐 low-level feature I_in ∈ R H×W×C를 추출
- 그다음 encoder-decoder 구조에 공급한 후 또 다른 Convolutional layer를 거쳐 I_out ∈ R H×W×C를 복원
- 마지막으로 I를 I_out에 skip-connection 하여 선명한 이미지 Y^를 생성 (Yˆ = I + LaKDNet(I))
LaKD Block

Feature Mixer와 Feature fusion 이라는 두 개의 하위 모듈로 구성.
Feature Mixer
- Feature Mixer는 Large kernel (e.g., 9x9)을 사용하는 depth-wise separable convolution과 유사한 개념을 가진다
- 이어서 kernel size 1x1의 point-wise convolution이 수행되며 그 사이의 inner shortcut이 있다
- Feature mixer는 공간적 intra-channel 및 깊이별 interchannel 특징을 개별적으로 처리
- 이러한 접근 방식은 넓은 공간적 위치 간 혼합을 가능하게 하며, Large kernel size와 결합되어 큰 ERF를 형성한다
Feature Fusion
- 로컬 정보 인코딩 효율성을 위해 kernel size 3x3의 depth-wise convolution layer로 구성
- 또한 게이팅 메커니즘을 도입하여 추가적인 경로를 추가. GELU 활성화 함수를 게이트로 사용
n번째 LaKD block에서 feature M_n을 출력하는 feature mixing 모듈을 다음과 같이 소개.

여기서 F^(n-1)은 n-1번째 LaKD block의 feature fusion 모듈의 출력 (1 < n ≤ N)
중간 feature z_k는 다음과 같이 재귀적으로 계산된다.
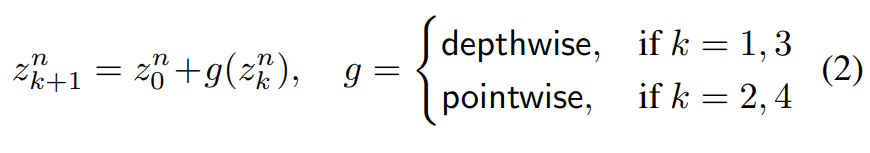

여기서 depthwise, pointwise 표기법은 각각 depth-wise, point-wise convolution을 나타내며,
LN은 layer normalization이다.
다음으로 feature fusion 과정에서 나온 output feature F_n을 다음과 같이 공식화.

- t^n=LN(M_n)
- W1 및 W2는 두 개의 별도 1x1 convolution layer
- ⊙는 요소별 곱셈 을 사용한 결합
- α는 GELU 활성화
- g는 3x3 커널을 사용한 깊이별 합성곱
... 중략
Conclusion
- 본 연구는 최근 모션, 디포커스 이미지 디블러링에서 지배적인 접근 방식인 Trasnformers와 대조되는 가벼운 CNN 아키텍처를 제시
- 대형 커널을 갖춘 핵심 구성 요소 LaKD Block은 대형 ERF로 이어지며, 단순성과 효율성을 유지하면서 최첨단 성능을 제공
반응형
'DeepLearning' 카테고리의 다른 글
| [Zero-DCE] Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement 리뷰 (0) | 2024.10.30 |
|---|