반응형
ResNet
- 2015년 ILSVRC에서 우승, MS 개발.
- 2014년 GooLeNet이 22개 층인데 반면 ResNet은 152개 층. (층수가 깊어졌다)
- 깊게 하면 무조건 성능이 좋은가? -> 아니다!
- Gradient Vanishing/Exploding
- 파라미터 개수가 너무 많아지는 문제 발생

Residual Block

기존 일반적인 CNN은 입력 데이터(x)를 타겟값(y)으로 mapping 하는 함수 H(x)를 찾는 것이 목표이다.
H(x) = ReLU ( w2 * ( ReLU ( w1 * x ) ) ) (w는 가중치)이때, H(x)와 y의 차이를 최소화하는 방향으로 학습하게 된다.
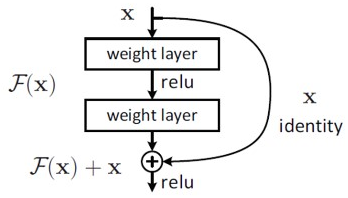
ResNet은 기존 CNN과 달리 입력값을 출력 값에 더하는 지름길(shortcut or skip-connection)이 있는 Residual Block 형태를 사용.
H(x) = F(x) + x = ReLU ( w2 * ( ReLU ( w1 * x ) ) ) + x입력값 x와 출력 값 H(x)의 잔차(residual)를 학습하는 것이 주목적이다.
H(x) - x를 최소화하는 방향으로 학습.
H(x) = F(x) + x
H(x) - x = F(x)즉 F(x)를 최소화 되게(0으로 수렴하는 방향으로) 학습.
여기서 한 가지 의문점이 들었던 게 그럼 F(x)가 0으로 수렴되면 결국 입력값이랑 출력 값이 같아지게 되는데 이게 무슨 소용인 거지?? 하는 의문이 들었다.
이는 애초에 ResNet에서는 H(x)가 identity function이라고 가정하고 만든 수식이므로 학습 결과가
H(x) := x로 나와야 하는 게 맞다.
* identity mapping : 입력값 x와 어떤 함수를 통과한 출력 값이 같아야 한다.
* identity function : identity mapping을 만족하는 함수.
Identity mapping
- F(x) = x
- 입력값을 그대로 전달.
- ResNet에서 shortcut(skip-connection)이 이 역할을 한다.
- 모델을 깊게 쌓아도 Gradient Vanishing/Exploding 문제를 해결.
Residual Block을 수식으로 다음과 같이 나타낼 수 있다.
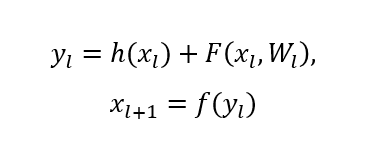
- y : 출력 값
- x : 입력값
- F : residual function
- h(x) : identity mapping
- f : ReLU
h, f가 identity function이면 다음 식이 성립

이 Residual Block을 l~L까지 쌓는다면 다음 식이 성립

이 식의 역전파 과정에서 다음 식을 얻을 수 있다.

위 식의 과정에서 항상 1이 남게 되면서 기울기 값이 소실되지 않게 되어 전달된다.
때문에 Gradient Vanishing 문제를 해결할 수 있게 됨.
Bottleneck
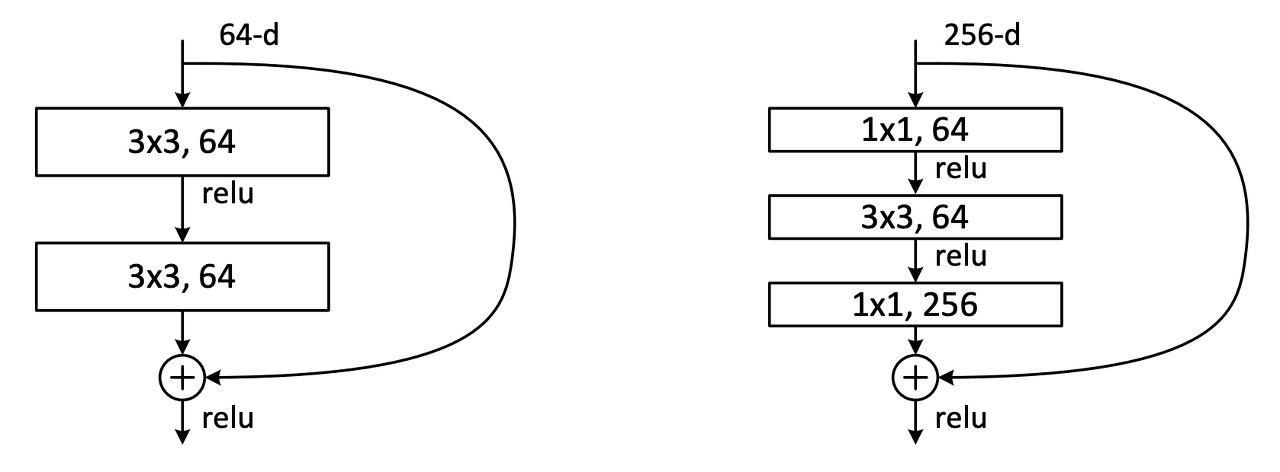
- 그림과 같이 Residual Block의 시작과 끝이 1x1 Convolution Layer를 추가.
- 1x1 conv layer는 네트워크 성능을 크게 저하시키지 않으면서 매개변수를 줄일 수 있다.
※ 1x1 convolution layer에 대한 이전글 참조
2021.08.17 - [DeepLearning/Concept] - 1x1 Convolution Layer
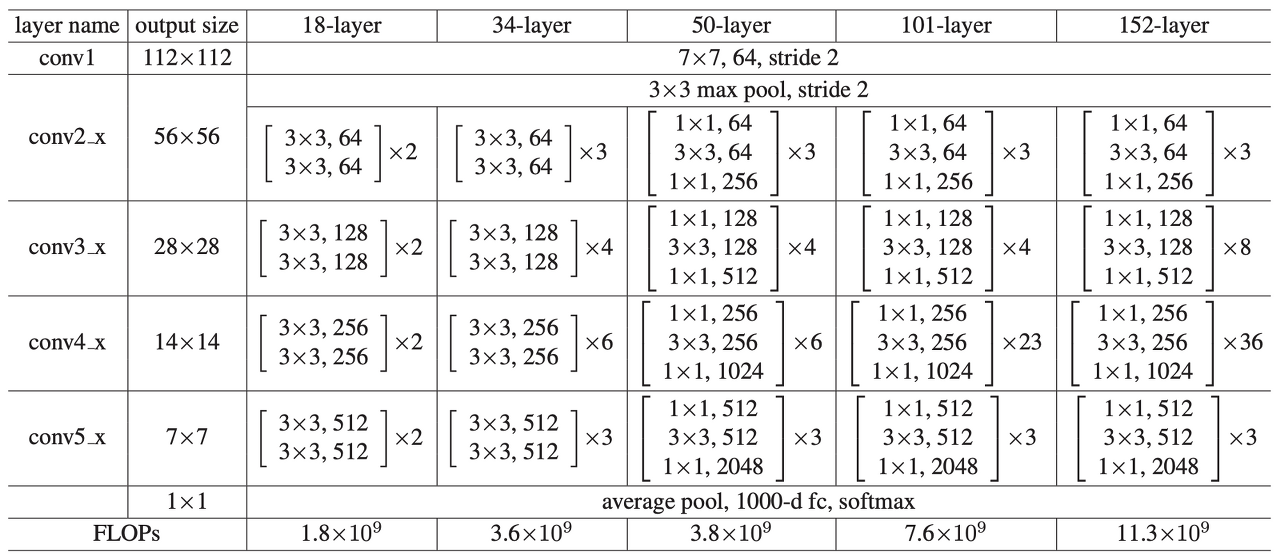
Struecture
논문에서 기재된 ResNet들의 구조.

반응형
'DeepLearning > Classification' 카테고리의 다른 글
| CBAM: Convolutional Block Attention Module 리뷰 (0) | 2024.05.29 |
|---|---|
| BAM: Bottleneck Attention Module 리뷰 (0) | 2024.05.23 |
| [Classification] VGGNet (0) | 2021.08.05 |
| [Classification] AlexNet (0) | 2021.08.03 |