반응형
Abstract
- feed forward CNN을 위한 간단하면서 효과적인 attention module인 CBAM을 제안.
- feature map이 주어지면 CBAM은 채널과 공간이라는 두 가지 개별 차원을 따라 attention map을 순차적으로 추론.
- CBAM은 가볍고 일반적인 모듈이기 때문에 모든 CNN에 원활하게 통합될 수 있으며 end-to-end 학습이 가능하다.
Keywords : Object Detection, attention mechanism, gated convolution
Introduction
- Attention은 어디에 집중해야 하는지 알려줄 뿐만 아니라 관심 표현도 향상시킨다.
- Attention mechanism을 사용하여 중요한 feature에 집중하고 불필요한 feature를 억제하여 표현력을 높임.
- 이를 위해 CBAM(Convolutional Block Attention Module)을 제안.
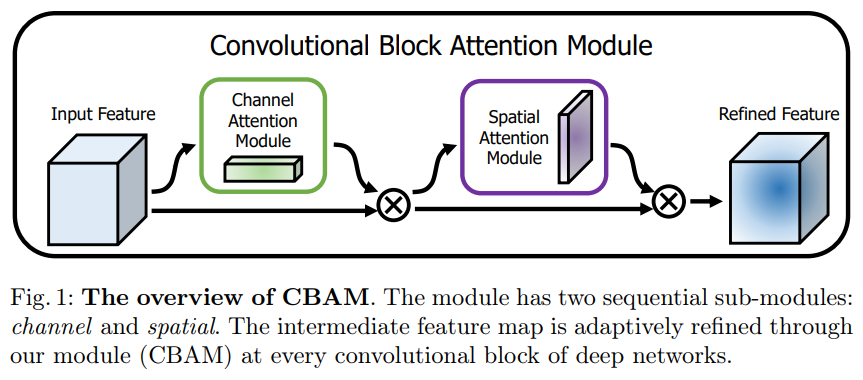
- CBAM은 채널 및 공간 Attention module을 순차적으로 적용.
- 각 branch가 채널 및 공간 축에서 '무엇'과 '어디'에 집중하는지 학습할 수 있도록 한다.
주요 기여 세 가지
- CNN의 표현력을 높이기 위한 효과적인 Attention module(CBAM)을 제안.
- 광범위한 연구를 통해 attention module의 효과를 검증
- 다양한 벤치마크에서 네트워크 성능이 향상되는 것을 확인.
Related Work
Network engineering
- CNN의 성공적인 구현 이후 다양한 아키텍처가 제안되었다.
- 직관적이고 간단한 확장 방법은 신경망의 깊이를 늘리거나, 넓이를 늘리는 연구가 진행되어 왔다. (ResNet, PyramidNet 등)
- ResNeXt에서는 그룹화된 Convolution 사용을 제안, cardinality를 높이면 정확도가 향상된다는 것을 연구.
- 본 논문에서는 네트워크 엔지니어링 방법으로 깊이, 너비, 카디널리티가 아닌 'Attention' 측면을 고려한다.
Attention mechanism
- 인간의 인식에 중요한 속성 중 하나는 전체 장면을 한 번에 처리하려고 하지 않는다는 점이다.
- 인간은 시각적 구조를 더 잘 포착하기 위해 선택적으로 일련의 부분에 초점을 맞춘다. (Attention)
- CBAM은 3D attention map을 직접 계산하는 대신 channel attention과 spatial attention을 각각 학습하는 과정으로 분해.
- 3D feature map에 대한 별도의 attention 생성 과정은 계산 및 파라미터 오버헤드가 훨씬 적다.
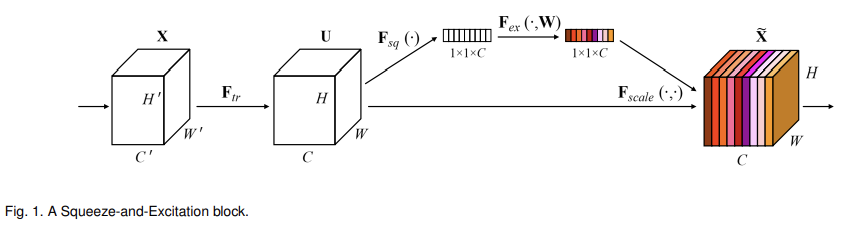
- Squeese-end-Excitation 모듈에서는 Global average pooling 된 feature를 사용하여 channel attention을 계산.
- CBAM에서는 channel attention에서 GAP뿐 아니라 Max pooiling feature도 추가적으로 사용.
Convolutional Block Attention Module
- CBAM은 feature map F∈R^(C×H×W)를 입력으로 Channel Attention Map M_c∈R^(C×1x1)과 2D Spatial Attention Map M_s∈R^(1 xHxW)를 순차적으로 추론.
- 전반적인 Attention 과정은 아래와 같다. (⊗:element-wise multiplication)
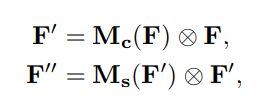
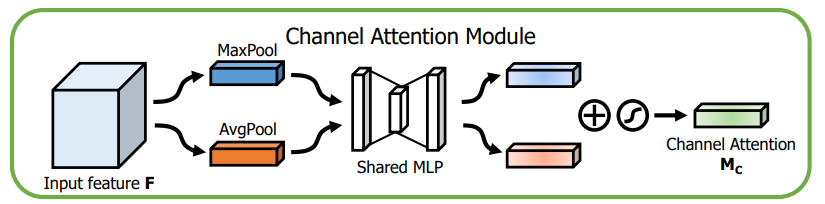
Channel attention module
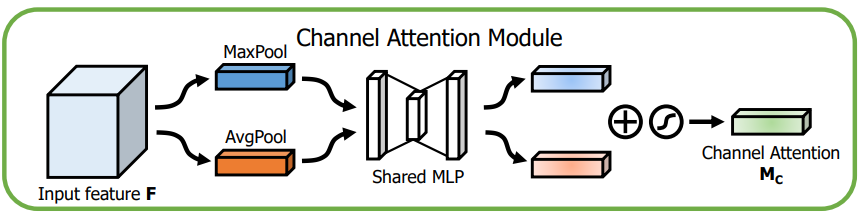
- Channel attention은 입력 이미지에서 '무엇'이 의미가 있는지에 초점을 맞춤.
- 효율적인 계산을 위해 feature map의 spatial dimension을 압축.
- BAM과 다르게 AvgPool 뿐 아니라 MaxPool을 동시에 사용.
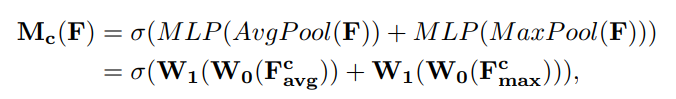
- 평균 풀링, 최대 풀링 작업을 통해 각 Fc_avg, Fc_max를 생성.
- Fc_avg, Fc_max는 공유 네트워크로 전달되어 Channel attention map Mc를 생성한다.
- 공유 네트워크는 하나의 hidden layer가 있는 MLP로 구성.
- 매개변수 오버헤드를 줄이기 위해 hidden layer 크기는 R^(C/r×1 ×1). (r은 축소비율)
- 공유 네트워크를 통과한 Fc_avg, Fc_max는 element-wise summation(요소 합)을 통해 병합.
- 병합된 feature는 시그모이드 함수를 통과해 최종 Channel attention map이 된다.
Spatial attention module
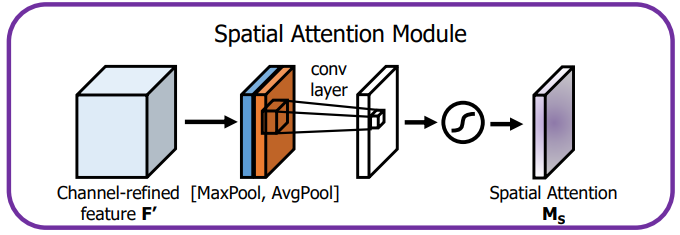
- Spatial attention은 '어디'에 의미가 있는지 초점을 맞춤.
- Spatial attention은 계산하기 위해 먼저 Channel dimension을 따라 AvgPool, MaxPool을 적용하고 이를 연결.
- 연결된 feature를 Convolution layer에 적용, 이를 시그모이드 함수를 통과시켜 Spatial attention map을 생성한다.
- 계산식은 아래와 같다. (f^(7x7)은 필터 크기가 7x7인 convolution 연산)

Arrangement of attention modules

- 입력 이미지가 주어지면 두 개의 attention module인 channel과 spatial이 각각 '무엇'과 '어디'에 초점을 맞춰 보완적인 attention을 계산한다.
- 이를 고려해서 두 개의 모듈을 병렬 또는 순차 방식으로 배치할 수 있는데, 본 논문에서는 순차적 배열 방식이 더 나은 것으로 소개한다.
Experiments
표준 벤치마크에서 CBAM을 평가.
Channel attention
- AvgPool과 MaxPool을 모두 사용하면 더 미세한 attention 추론이 가능하다는 것을 실험적으로 검증.
- AvgPool만 사용, MaxPool만 사용, 두 풀링의 공동 사용을 비교.
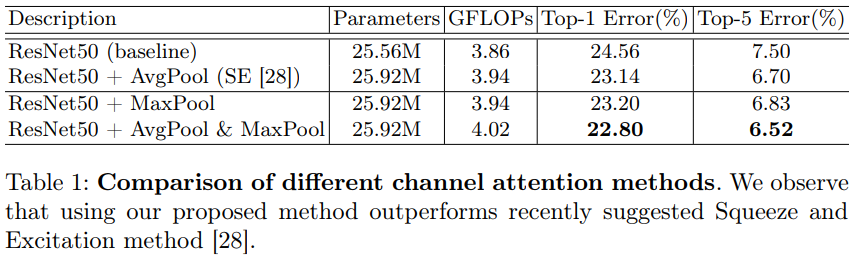
- Table 1을 참고하면 Max Pool이 Avg Pool 만큼 의미 있음을 관찰.
- 또한 두 Pooling을 모두 사용하는 것이 가장 효과적임을 관찰.
Spatial attention
- 채널 차원 전체에 걸쳐 Avg 및 Max Pooling을 사용하는 방법과, 채널 차원을 1로 줄이는 표준 1x1 Convolution을 비교.
- 또한 커널 크기의 효과를 조사.
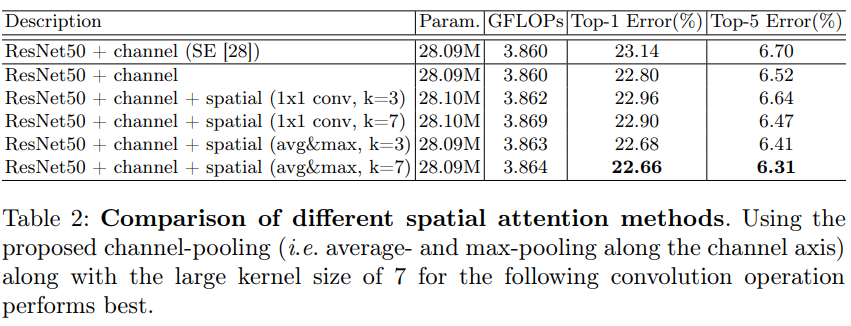
- Table 2를 통해 spatial attention을 추가함으로 더 나은 정확도를 생성한다는 것을 관찰.
- 또한 1x1 convolution의 구현보다 avg&max pooling이 더 미세한 추론을 가능 캐 한다는 것을 확인.
- convolution 커널 크기를 비교했을 때 3보다 7이 더 효과적임을 확인.
- 이는 공간적으로 중요한 지역을 결정하기 위해 큰 receptive field가 필요함을 입증한다.
Arrangement of the channel and spatial attention
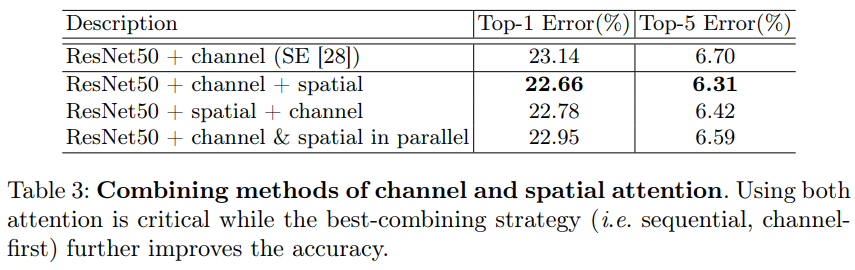
- 채널 및 공간 attention 서브모듈을 배열하는 세 가지 방법을 비교.
- Attention map을 순차적으로 생성하는 것이 병렬로 생성하는 것보다 성능이 좋음을 확인.
- 또한 채널 우선 순서가 공간 우선 순서보다 성능이 약간 더 좋음을 확인.
Conclusion
- CNN Network의 성능을 향상시키는 새로운 접근 방식인 CBAM을 제시.
- 채널과 공간 두 가지 고유한 attention 기반 모듈을 사용하여 기능을 개선.
반응형
'DeepLearning > Classification' 카테고리의 다른 글
| BAM: Bottleneck Attention Module 리뷰 (0) | 2024.05.23 |
|---|---|
| [Classification] ResNet (0) | 2021.09.10 |
| [Classification] VGGNet (0) | 2021.08.05 |
| [Classification] AlexNet (0) | 2021.08.03 |