Abstract
- YOLO 이전 Object Detection 시스템은 위치 정보를 추론하고 그 위치에서 Classification을 하는 방식의 복잡한 파이프라인 구조였다.
- YOLO는 end-to-end 형식의 하나의 Convolution Network로 이미지 전체에서 위치 정보와 클래스 확률을 한 번에 추론한다.
- 그래서 매우 빠르다.
Introduction
DPM (Deformable Parts Models)
- DPM은 슬라이딩 윈도우 방식으로, 전체 이미지에 균일한 간격의 위치에서 Classification을 진행.
R-CNN
- 영역 제안(Region Proposal) 방식을 사용하여 이미지에서 객체가 있을법한 잠재적 위치를 생성.
- 그 위치에 대해 Classification을 진행.
위 두 가지 방식은 복잡한 파이프라인이며 속도가 느리다는 단점이 있다.

YOLO
- YOLO는 단일 Convolution Network로 여러 바운딩 박스와 해당 박스에 대한 클래스 확률을 동시에 예측한다.
- 복잡한 파이프 라인이 필요하지 않기 때문에 매우 빠르다.
- 슬라이딩 윈도우 방식이나 영역 제안 방식과는 달리 YOLO는 전체 이미지를 확인하므로 객체의 모양은 물론 상황별 정보를 암시적으로 인코딩하여 이미지에 대해 전역적으로 추론한다.
Unified Detection

통합 감지
1) 입력 이미지를 S x S Grid로 나눈다. 물체(bbox)의 중심이 Grid cell에 들어가면 해당 Grid cell이 해당 물체를 감지하는 역할을 한다.
2) 각 Grid cell은 B개의 바운딩 박스와 해당 박스에 대한 Confidence Score(신뢰도 점수)를 예측한다.

- Confidence Score(신뢰도 점수)는 바운딩 박스에 객체가 포함되어 있는지를 예측한다. ( Pr(Object) )
- 또한 바운딩 박스 예측이 얼마나 정확한지 반영한다. ( IoU )
- 해당 셀에 객체가 없다면 신뢰도 Pr(Object) = 0
- 해당 셀에 객체가 있다면 예측된 바운딩 박스와 실제값 사이의 IoU값이 된다.
3) 각 바운딩 박스는 5개의 예측값을 포함한다.
- x, y : Grid cell의 경계를 기준으로 bbox의 중심.
- w, h : 전체 이미지를 기준으로 bbox의 넓이, 높이.
- confidence : 신뢰도 점수.
4) 각 Grid cell은 조건부 클래스 확률을 예측한다.

- Grid cell에 객체가 있을 때 그 객체가 Class_i일 확률.
- 바운딩 박스(B)의 수와 상관없이 Grid cell 하나당 하나의 class만 예측한다.
5) Test time에 조건부 클래스 확률과 각 바운드 박스의 Confidence Score 예측을 곱한다.
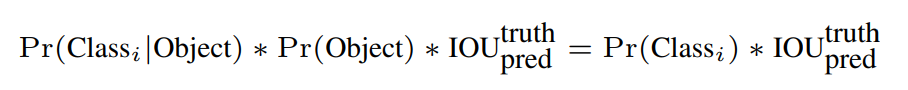
- 이는 각 바운딩 박스에 대한 클래스별 신뢰도 점수를 제공한다.
- 이 점수는 해당 클래스가 바운딩 박스에 나타날 확률과 예측된 바운딩 박스가 Object에 얼마나 잘 맞는지 모두 인코딩한다.
6) 본 논문에서는 S=7, B=2, C=20으로 설정하여 최종적으로 7x7x30의 output tensor를 예측하게 된다.
Network Design

- Yolo model은 24개의 Convolution Layer들과 2개의 Fully Connected Layer로 구성.
- Convolution Layer에서는 이미지의 특징을 추출, Fully Connected Layer는 output 확률과 좌표를 예측한다.
- Network의 최종 ouput은 7x7x30 크기의 텐서를 예측.
Inference
- Yolo는 이미지당 98개의 bbox와 각 bbox의 클래스 확률을 예측.
- Classifier 기반 방법과 달리 단일 네트워크 evaluation만 필요하므로 매우 빠르다.
- NMS(Non-Maximal Suppression)을 사용하여 다중 감지를 수정한다.
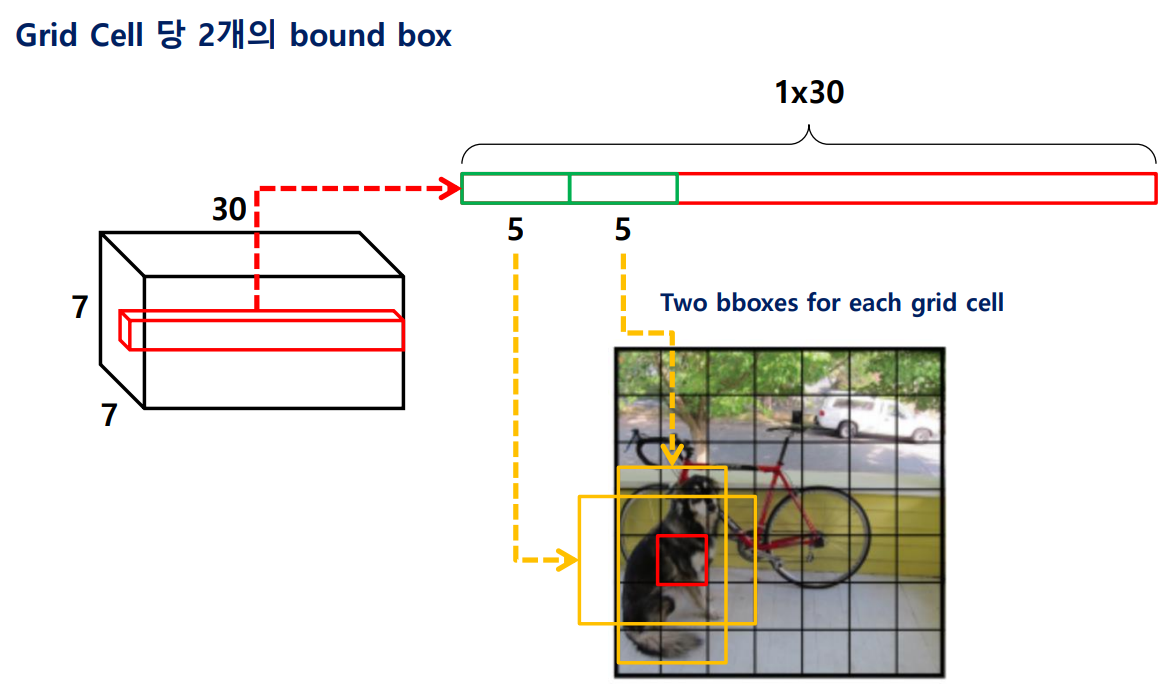
1) Grid Cell 하나는 아래와 같이 1x1x30 크기의 tensor로 표현.

2) Grid Cell 하나당 2개의 bbox 정보를 포함.
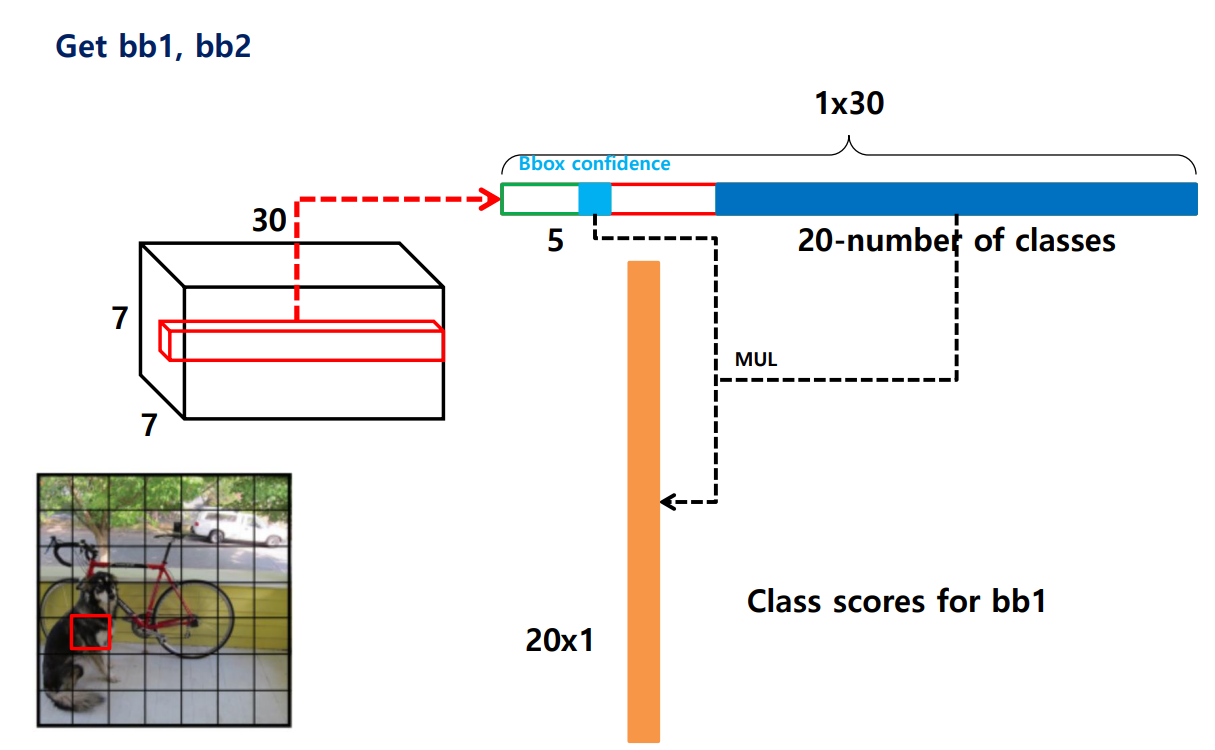
3) Grid Cell 하나당 20개의 조건부 클래스 확률을 예측. 조건부 클래스 확률과 bbox confidence score를 곱해 Class Score for bbox를 예측.
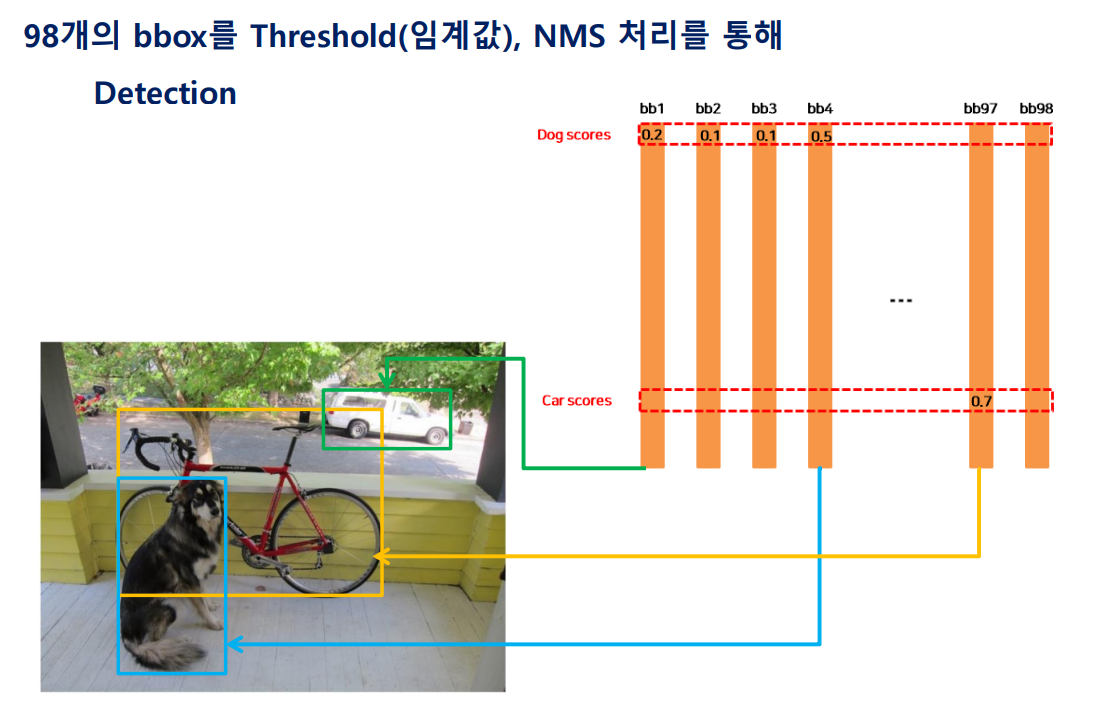
4) 모든 Grid cell에 대해 같은 연산처리를 하면 7x7x2=98개의 bbox 정보를 가지게 된다.


5) 이후 각 bbox 정보에 대해 Threshold, NMS 처리를 통해 최종적인 Object Detection 결과를 도출.
Limitations of YOLO
- YOLO는 각 Grid cell이 두 개의 bbox만 예측하고 하나의 클래스만 예측할 수 있으므로 공간적 제약이 있다.
- 이러한 공간적 제약으로 인해 모델이 예측할 수 있는 인근 객체의 수가 제한된다. (새 떼와 같은 그룹으로 나타나는 작은 물체를 처리하는데 어려움이 있다)
- 손실 함수를 학습하는 동안 작은 bbox와 큰 bbox의 오류를 동일하게 처리하는데, 일반적으로 큰 bbox의 작은 오류는 무해하지만 작은 bbox의 작은 오류는 IoU에 훨씬 큰 영향을 미친다. (작은 개체 Detection에 어려움이 있음)
'DeepLearning > Detection' 카테고리의 다른 글
| [Detection] SSD : Single Shot MultiBox Detector (2) | 2024.02.16 |
|---|---|
| [Detection] Anomaly Detection (0) | 2021.03.15 |