0. Abstract
- 단일 심층 신경망을 사용하여 이미지에서 객체를 탐지하는 방법을 제시.
- SSD의 접근 방식은 bbox의 출력 공간을 다양한 종횡비 및 feature map 위치별 크기에 대한 default box 세트로 분리.
- 예측 시 네트워크는 각 default box에 있는 각 class score를 생성하고 객체 모양에 더 일치하도록 조정.
- network는 다양한 해상도의 여러 feature map의 예측을 결합하여 다양한 크기의 객체를 자연스럽게 처리.
- SSD는 모든 계산을 단일 네트워크에 캡슐화하기 때문에 object proposal이 요구되는 방법에 비해 간단하다.
1. Introduction
- 기존 Faster R-CNN을 기반의 접근 방식은 정확하기는 하지만 너무 느려 실시간 애플리케이션에 적합하지 않다.
- 속도의 근본적인 개선은 bbox proposal과 후속 pixel 또는 feature 리샘플링 단계를 제거함으로써 이루어진다.
- bbox 위치에서 object categories 및 offset을 예측하기 위한 작은 convolution 필터 사용.
- 다양한 종횡비 감지를 위한 별도의 predictor(필터) 사용.
- 이러한 필터를 네트워크 후반 단계에서 여러 feature map에 적용하는 것이 포함된다.
- 특히 다양한 스케일에서 예측을 위해 여러 layer를 사용해 높은 정확도와 검출 속도를 더욱 높였다.
2. The Single Shot Detector (SSD)
제안된 SSD 프레임워크와 Training 방법에 대해 설명.

2.1 Model

- SSD feed-forward convolution network를 기반으로 한다.
- 초기 network layer는 고품질 이미지 분류에 사용되는 표준 architecture(VGG-16)를 기반으로 하며, 이를 기본 네트워크(base network)라고 한다.
- 그런 다음 네트워크에 보조 구조를 추가하여 다음과 같은 주요 기능을 갖춘 탐지를 생성한다.
Multi-sacle feature maps for detection
- 기본 네트워크(base network) 끝에 convolutional feature layer를 추가한다.
- 이러한 레이어의 크기는 점진적으로 감소하며 다양한 규모의 탐지 예측이 가능하다.

Convolutional predictors for detection
- 추가된 각 feature layer는 일련의 convolutional 필터들을 사용하여 검출 예측들의 고정 세트를 생성한다.
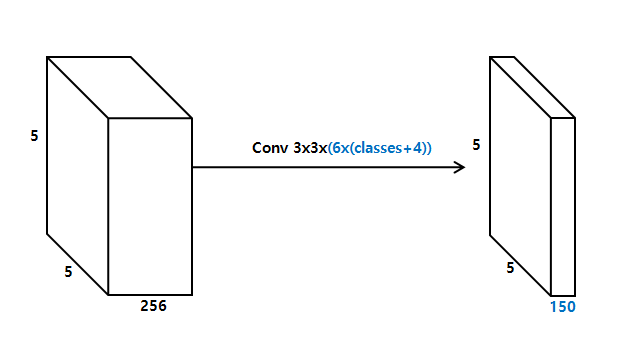
- p개의 채널이 있는 m x n 크기의 feature layer의 경우, 잠재적 검출의 파라미터를 예측하기 위한 기본 요소는 카테고리에 대한 점수 또는 defualt box에 대한 모양 offset을 생성하는 3 x 3 x p 작은 커널이다.
- 커널이 적용된 m x n 위치 각각에서 출력값을 생성.
- bbox offset 출력 값은 각 feature map 위치에 대한 defualt box 위치를 기준으로 측정된다.

Default boxes and aspect ratios
- network 상단의 여러 feature map에 대해 default box 세트를 각 feature map cell과 연결.
- defualt box는 feature map을 나선형 방식으로 타일링하므로 해당 cell을 기준으로 각 box의 위치가 고정된다.
- 각 feature map cell에서 cell의 defualt box 모양을 기준으로 한 offset과 각 box에 class 인스턴스가 있음을 나타내는 class별 점수를 예측한다.
- 구체적으로, 주어진 위치에 있는 k개 중 각 box에 대해 c 클래스 점수와 원래 default box 모양을 기준으로 4개의 offset을 계산.
- 결과적으로 feature map의 각 위치 주위에 총 (c+4)k 필터가 적용되어 m x n feature map에 대한 (c+4)kmn 출력이 생성. (즉, [{class + (x, y, w, h)} * k개의 default box] * m * n 이 된다)
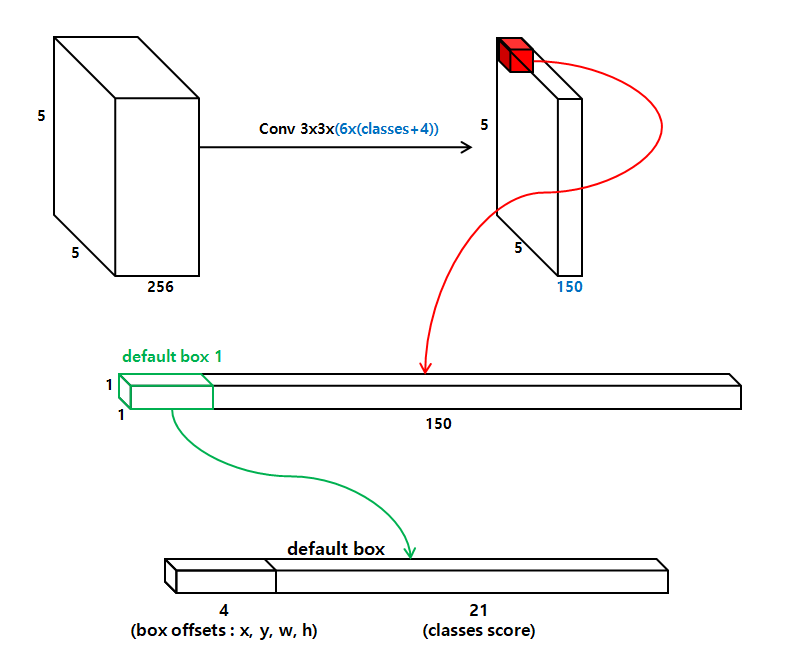
- default box는 Faster R-CNN에서 사용된 anchor box와 유사하지만 이를 다른 해상도의 여러 feature map에 적용한다는 점에서 차이가 있다.
2.2 Training
- SSD와 region proposal을 사용하는 다른 모델들의 Training에 있어 주요 차이점은 고정된 detector output 세트의 특정 출력에 ground truth를 할당해야 한다는 것이다.
- Training에는 탐지를 위한 default box 및 scale 세트 선택을 물론, hard negative mining 및 data augumentation 전략도 포함된다.
Matching strategy
- 훈련 중에 어떤 default box가 ground truth detection에 해당하는지 결정해야 한다.
- default box에서 ground truth box을 선택한다.
- 각 groung truth box를 jaccard overlap(IoU와 같은 것)을 이용하여 최상의 default box와 일치시킨다.
- 이때 jaccard overlap의 임계값은 0.5. (0.5보다 높은 default box를 모두 일치시킴)
- 이는 학습 문제를 단순화하여 네트워크가 최대로 겹치는 default box만 선택하도록 하는 작업이다.
Training objective
SSD 훈련 목표는 MultiBox 목표에서 파생되어 여러 개체 범주를 처리하도록 확장되었다.

- (x_ij)^p : 클래스 p에 대해, i번째 default box와 j번째 ground truth box의 매칭 지표.
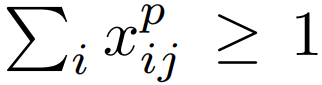
- 위 Matching strategy 내용을 바탕으로 모든 (x_ij)^p의 합이 1보다 크다.

- 전체 objective 손실 함수는 localization loss(loc)와 confidence loss(conf)의 가중 합계.
- N은 일치하는 default box의 개수. (N=0인 경우 손실을 0으로 설정)
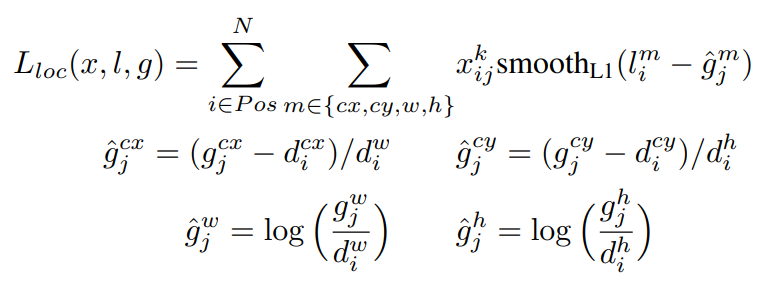
- localization loss는 predict box(l)와 ground truth box(g) 사이의 Smooth L1 손실이다.
- cx, cy : default box 중심.
- w, y : default box 너비 및 높이.
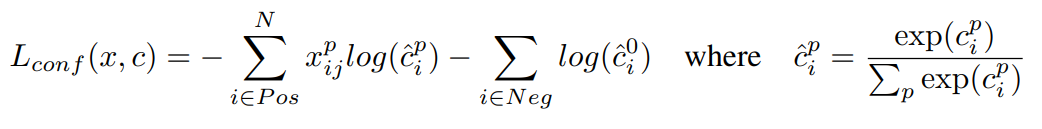
- confidence loss는 여러 class confidence에 대한 softmax loss이다.
- 가중치 α는 교차 검증을 통해 1로 설정.
Choosing scales and aspect ratios for default boxes

- SSD의 다양한 크기의 feature map은 서로 다른 receptive field를 가지고 있다.
- 위 그림의 8x8 feature map과 4x4 feature map에서 같은 크기의 커널이 감싸는 영역은 scale 면에서 차이가 나기 때문에 서로 다른 크기의 객체 탐지를 용이하게끔 학습한다.
- 특정 크기의 feature map이 객체의 특정 scale에 반응하는 방법을 학습할 수 있도록 default box의 타일링을 설계한다.

- 예측을 위해 m개의 feature map을 사용한다고 가정했을때, 각 feature map의 default box 크기는 위와 같이 계산된다.
- S_min는 0.2이고 S_max는 0.9이다. 즉 가장 낮은 layer의 scale은 0.2이고 가장 높은 layer의 scale은 0.9.
- 본 논문에서 m=6이므로, S_k = [0.2, 0.34, 0.48, 0.62, 0.76, 0.9]가 된다.
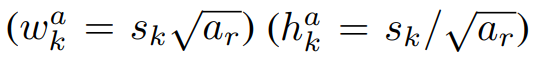
- default box에 대해서 서로 다른 종횡비를 적용하고 이를 a_r ∈ {1, 2, 3, 1/2 , 1/3 }로 표시한다.
- 각 default box의 너비((w_k)^a)와 높이((h_k)^a)를 계산할 수 있다.
- a_r 값대로 default box들의 종횡비를 결정 했다고 보면 될 듯...
Hard negative mining
- matching step 이후에는 대부분의 default box가 negative(객체가 아님)이다. (-> 이미지 대부분이 배경이기 때문)
- 이로 인해 training 시, positive example과 negative example 사이에 심각한 불균형이 발생.
- 모든 negative default box를 사용하지 않고, 그중 가장 confidence loss가 높은 negative default box를 positive default box와 비율이 최대 3:1이 되도록 추려서 학습한다.
- 본 논문에선 이런 작업이 더 빠른 최적화와 안정적인 학습으로 이어진다는 것을 발견했다.
'DeepLearning > Detection' 카테고리의 다른 글
| [Detection] YOLO 논문 리뷰, 분석 (You Only Look Once: Unified, Real-Time Object Detection) (2) | 2024.01.31 |
|---|---|
| [Detection] Anomaly Detection (0) | 2021.03.15 |