Segmentation?
Segmentation이란 이미지상의 물체들을 픽셀 단위로 분할, 검출하는 것이다. Segmentation은 구체적으로 Sementic Segmentation과 Instance Segmentation으로 나뉜다.
Sementic Segmentation은 물체를 검출함에 있어 같은 class의 물체는 서로 구분 짓지 않고 검출한다. 반면 Instance Segmentation은 같은 class의 물체라도 서로 다른 객체로 구분 지어 검출하는 것이다.

FCN은 Sementic Segmentation의 대표적인 모델 중 하나이다.
CNN 한계
FCN은 어떻게 물체를 구분 짓고 픽셀 단위로 검출할 수 있을까? 이런 FCN의 동작 원리를 알기 앞서 CNN의 특징에 대해 알아보자.
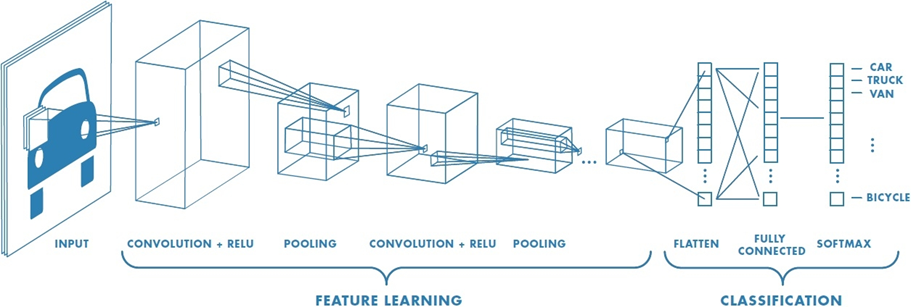
CNN은 대부분 모델의 구조는 Convolution Layer를 통해 특징을 뽑아낸 후 FC(Fully Connected) Layer를 거쳐 이미지가 어떤 class인지 분류하게 된다.
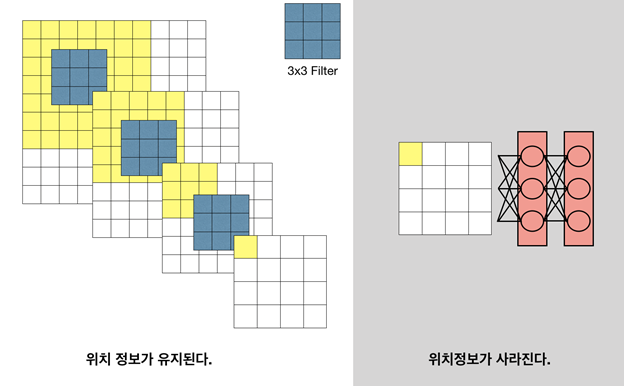
문제는 FC Layer에 들어간 특징들은 위치정보가 소실되어 class는 분류하지만 class에 해당하는 물체가 어디에 존재하는지는 알 수 없다는 것이다.
FCN
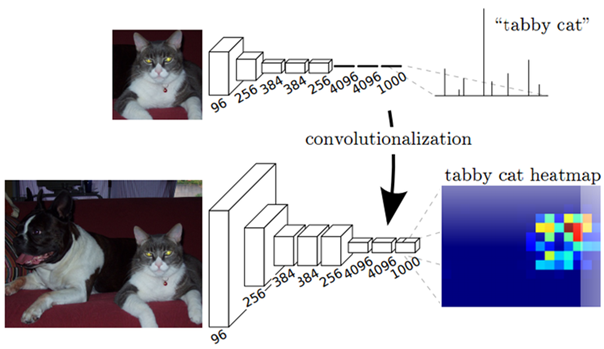

FCN(Fully Convolutional Network)은 이러한 CNN의 한계(위치 정보를 알 수 없는 점)를 극복하기 위해 마지막 FC Layer를 Convolutional Layer로 대체하였다.
위 왼쪽 그림과 같이 Conv Layer를 거쳐 얻은 특징 맵(heatmap)을 통해 위치정보를 유지할 수 있게 되었다.
하지만 이러한 heatmap은 대략적인 정보만을 가지고 있기 때문에 원래의 이미지 크기로 다시 복원해줄 필요가 있다. 이러한 복원 과정을 Deconvolution 혹은 Upsampling이라고 한다.
Deconvolution(Upsampling)
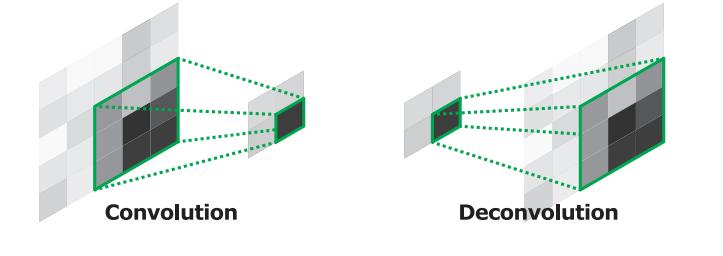
Convolution이 특징을 추출하면서 크기를 줄여가는 역할이었다면, Deconvolution은 추출된 특징의 정보로부터 크기를 키워주는 역할을 한다.

FCN 논문에서는 위 그림의 과정과 같이, Convolution Layer를 거쳐 1/32배 줄어든 특징 맵을 stride 32로 바로 Upsampling을 하여 특징 맵을 원래 이미지 크기로 만든다.
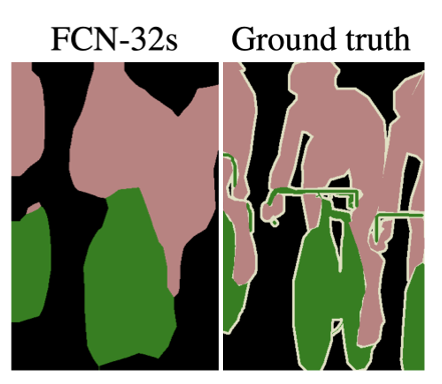
하지만 Conv Layer를 거치면서 원래의 형태 정보가 훼손되었기 때문에 stride 32로 단순히 Upsampling을 한 결과 이미지는 뭉뚝하게 망가진 형태로 보이게 된다.
Skip Combining
FCN 논문에서는 좀 더 명확한 결과 이미지를 얻기 위한 방법으로 Skip Combining 기법을 소개한다.
Skip Combining은 Conv Layer 과정에서 나오는 중간 Layer들의 특징 맵의 정보도 활용하는 기법이다. (이전 Layer의 특징 맵은 좀 더 디테일한 위치 정보를 가지고 있기 때문)
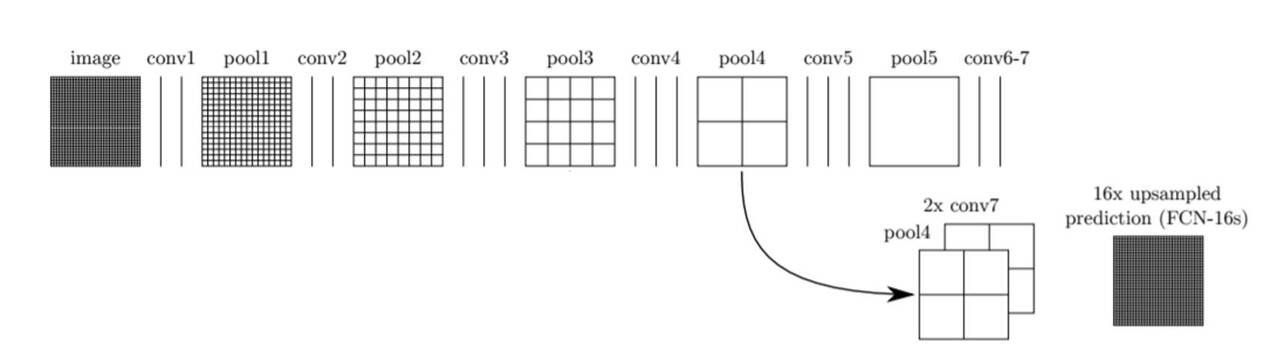
위 그림을 토대로 Skip Combining의 방법을 설명하자면,
- Conv Layer의 마지막 특징 맵인 conv7을 2배 Upsampling. (FCN-32s에서는 이 conv7을 바로 32배 Upsampling)
- 이전 특징 맵인 pool4와 conv7을 합해줌.
- 더한 특징 맵을 16배 Upsampling. (FCN-16s)

Skip combining을 활용한 결과 좀 더 디테일한 Segmentation을 할 수 있게 되었다. 마찬가지로 전전 특징 맵을 Skip combinig 하여 더욱 디테일한 이미지를 얻을 수 있게 된다.


끝.
'DeepLearning > Segmentation' 카테고리의 다른 글
| [Deblurring] Rethinking Coarse-to-Fine Approach in Single Image Deblurring (MIMO-UNet) (0) | 2024.05.27 |
|---|---|
| [Segmentation3D] PointNet (0) | 2021.01.25 |
| [Segmentation] SegNet (0) | 2021.01.08 |
| [Segmentation] U-Net (0) | 2021.01.08 |