PointNet
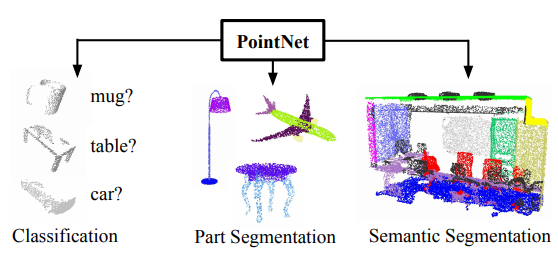
- PointNet은 3D data인 point data를 Classification, Segmentation 하기 위한 모델이다.
- 2D data와 달리 3D data는 정규화 데이터가 아니고, 불규칙하게 얻어진다. (2d는 행렬로 regular 하게 얻어진다)
- 특정 rendering 없이 point data를 다루기 위해서는 2가지 성질을 만족해야 한다.
1. Permutation invariant
2. Rigid motion invariant
Permutation invariant
3d point는 특정 순서 없이 주어지기 때문에 어떠한 순서로 오더라도 output이 달라지면 안 된다. 이를 Permutation invariant(직역하면 순열 불변)라고 한다.
PointNet에서는 Permutation invariant의 성질을 만족하기 위해 Symmetric function을 제안한다.
Symmetric function
Symmetric function이란 변수들의 순서가 바뀌어도 결과가 같은 함수를 뜻한다. ( 곱셉, 덧셈 등. f(x, y, z) = f(z, x, y) )
논문에서는 symmetric function으로 max pooling을 제안한다. symmetric function의 구조는 아래 그림과 같다.
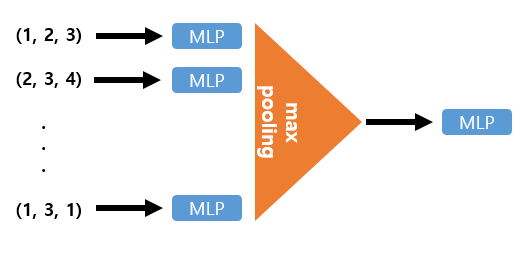
1. 각 point마다 MLP에 통과시켜 feature를 뽑아낸 뒤(이때 MLP의 weight는 모든 point마다 동일하게 사용된다)
2. 이 feature들을 max-pooling 하여 Permutation invariant(순열 불변)하게 만든다.
symmetric function의 구조를 좀 더 자세히 살펴보자.
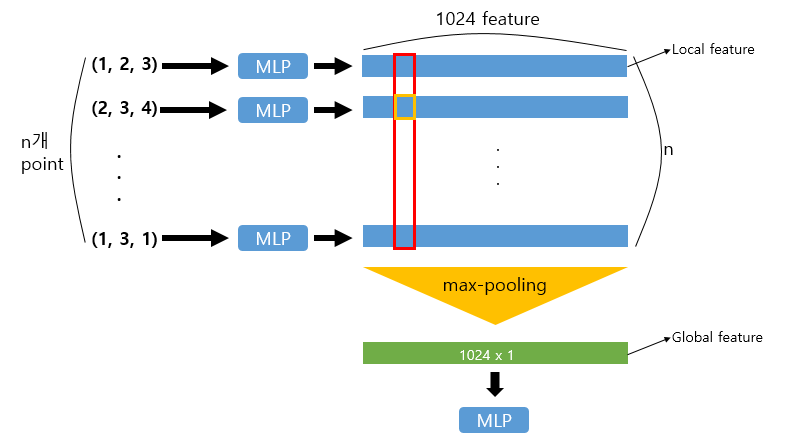
각 point들은 MLP를 지나 각 1024개의 feature를 생성하게 되고, 이 feature를 다시 max pooling 하여 모든 점들의 global feature를 생성하게 된다.
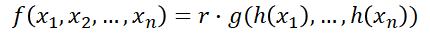
수식의 r, h는 MLP, g는 max pooling이다.
Rigid motion invariant
3d data는 순열 불변 말고도, Rigid motion invariant를 만족해야 한다.
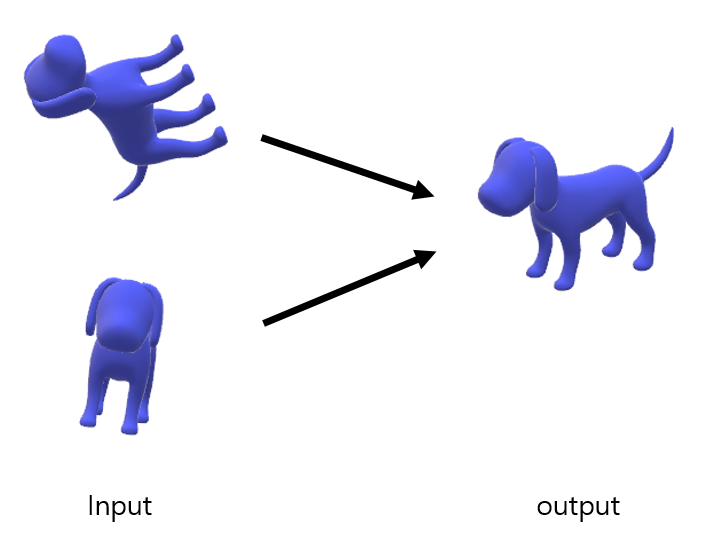
Rigid motion invariant란 input data에 어떤 transformation이 가해져도 output이 달라지면 안 된다는 것이다.
2d image에서는 transformation 가해진 이미지를 원래 이미지로 되돌리기 위해 STN(Spatial Transformer Network)을 사용한다. STN을 간단하게 설명하면 다음과 같다.
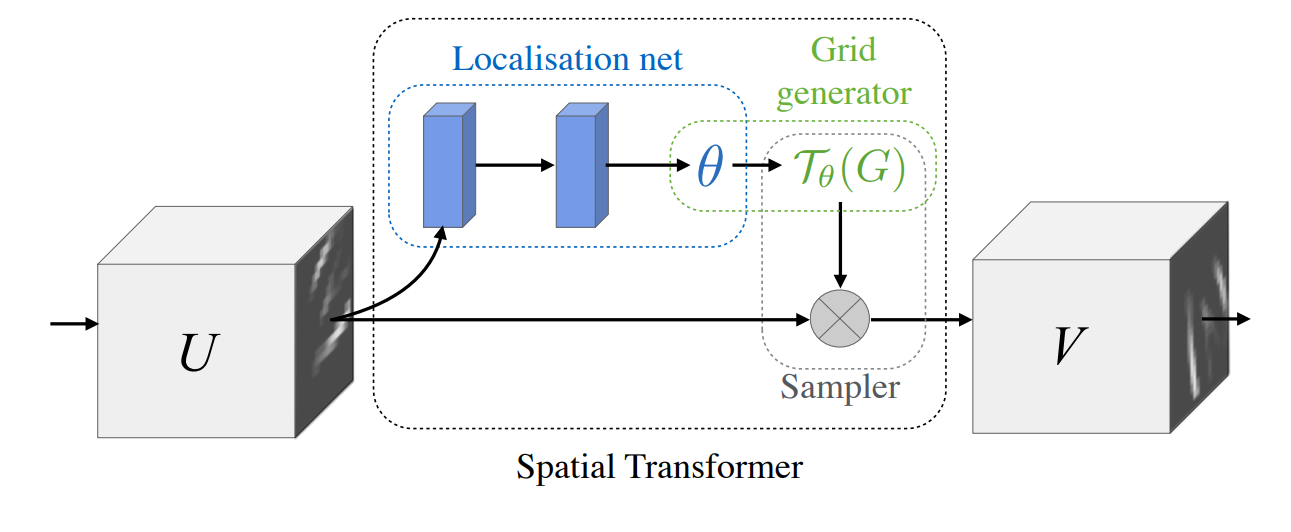
- localisation net에서 FC 혹은 Convolution을 이용하여 θ를 찾아낸다.
- Grid generator에서는 localisation net에서 찾은 θ를 이용하여 transform matrix를 맵핑.
- Sampler 단계에서 입력 U와 transform matrix를 입력을 곱해 변형이 일어나지 않은 output을 얻는다.
PointNet에서는 이 STN의 아이디어를 가져와 T-Net이란 걸 제안.
T-Net (mini pointNet)
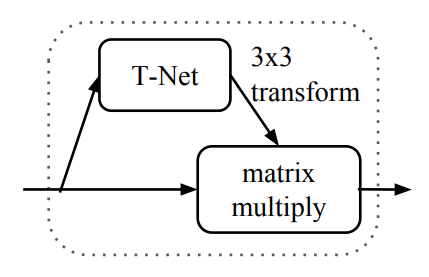
T-Net은 STN 구조와 동일한 형태로 mini pointNet이라고도 한다.

- 위 그림과 같이 T-Net에서는 STN에서와 같이 mini pointNet을 통해 transformation matrix를 계산.
- input data에 transformation matrix를 곱하여 변형이 일어나지 않은 output을 얻는다.
PointNet Architecture
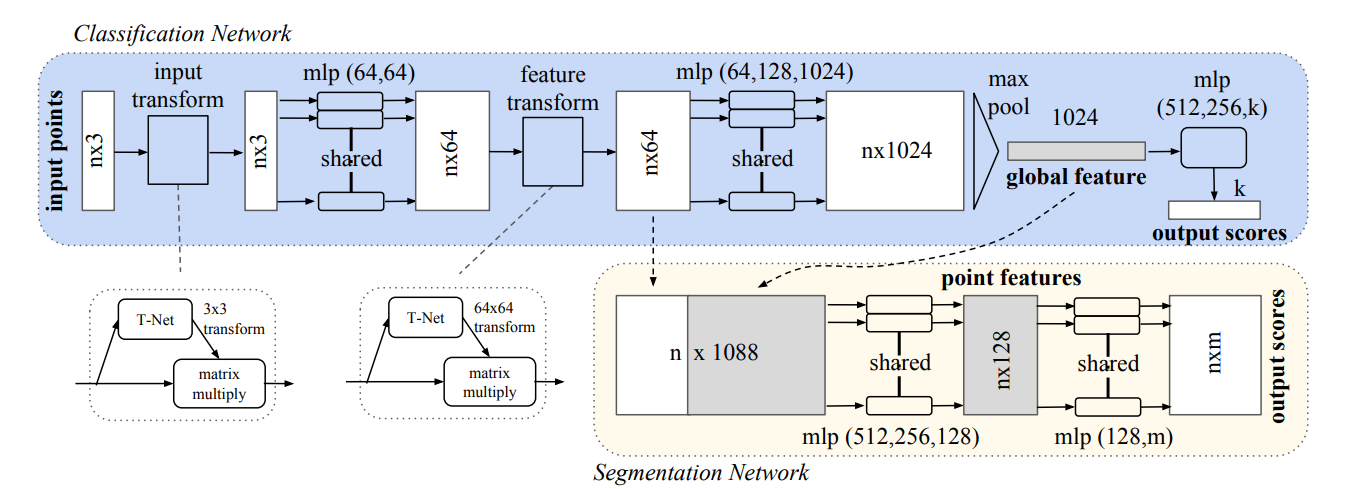
이제 PointNet의 전체 구조를 살펴보자.
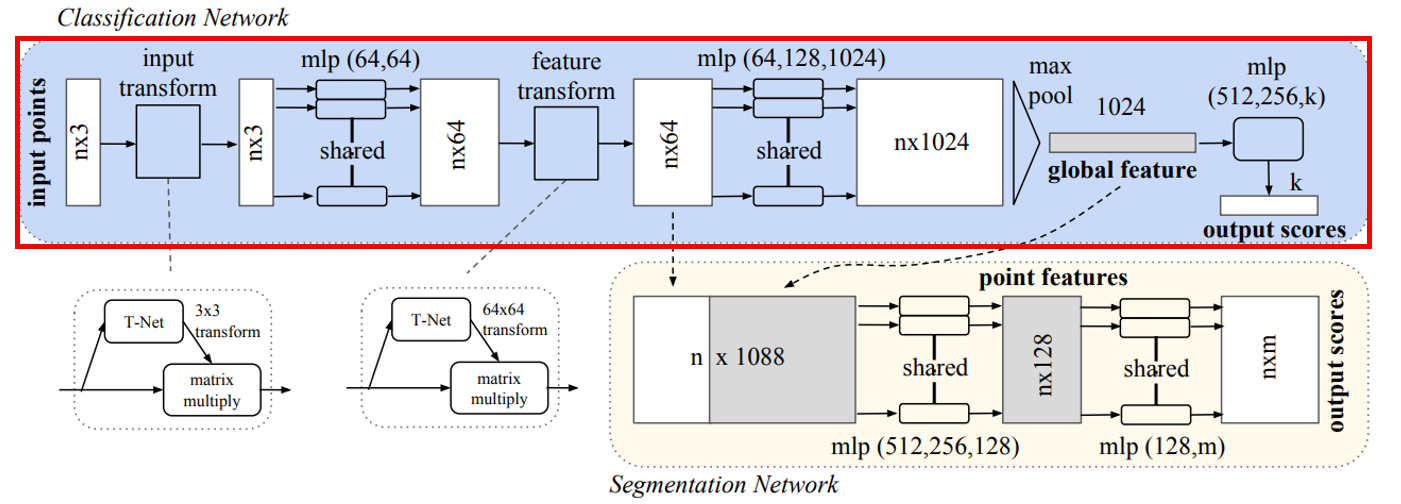
윗부분을 먼저 설명.
- n개의 point data를 MLP를 통해 feature를 뽑아내고,
- 그 feature들을 Max pooling 하여 global feature 추출.
- global feature에 대해 다시 한번 MLP를 통해 k개의 ouput scores를 뽑아낸다. (k=class 개수)
하지만 이 와 같은 구조는 Classification의 구조이다.
Segmentation을 위한 구조는 아래와 같다.
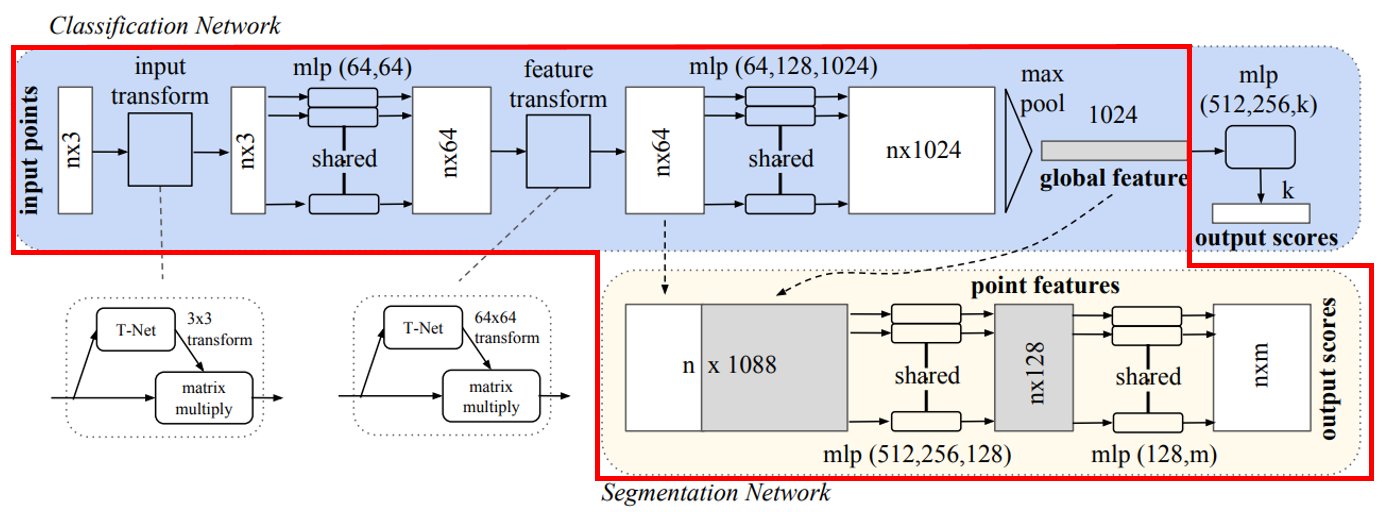
- n개의 point data를 MLP를 통해 feature를 뽑아내고,
- 그 feature들을 Max pooling 하여 global feature 추출.
- 64개의 feature가 생성된 중간 layer에 global feature를 붙여 MLP를 통과 nxm크기의 output 출력.
Segmentation에서는 각 point마다의 local feature 64개 뒤에 global feature 1024개를 붙여, local & global 정보를 결합.
T-Net은 전체 구조에서 point data들의 local featrue를 뽑아내는 과정에서 Rigid motion invariant을 위해 사용된다.
- input transform에서는 T-Net을 이용하여 3x3 transform matrix 구함.
- feature transform 부분에서는 64x64 크기의 transfrom matrix를 구함.
- 64x64 크기는 3x3크기에 비해 차원이 커서 Optimization 하기 어렵다.
따라서 transform matrix를 A로 설정하고 다음과 같은 정규화 수식으로 Loss Function을 설정한다.
Regularization term
A와 직교 행렬 A^T는 서로 곱하면 I가 되기 때문에, I와의 차의 절댓값이 작아지는 쪽으로 학습하면 A는 원래 구하려는 transform matrix에 근사해지기 때문에 위와 같은 정규화 식으로 A를 구한다.


끝.
'DeepLearning > Segmentation' 카테고리의 다른 글
| [Deblurring] Rethinking Coarse-to-Fine Approach in Single Image Deblurring (MIMO-UNet) (0) | 2024.05.27 |
|---|---|
| [Segmentation] SegNet (0) | 2021.01.08 |
| [Segmentation] U-Net (0) | 2021.01.08 |
| [Segmentation] FCN, Fully Convolutional Network (0) | 2021.01.07 |