반응형
Abstract
- 기존 coarse-to-fine 전략의 여러 서브 네트워크를 쌓아 다중 스케일 입력 이미지를 처리, 하위~상위 네트워크로 이미지 선명도를 점차 개선한다.
- 이러한 coarse-to-fine 전략은 높은 계산 비용을 초래.
- 본 논문은 MIMO-UNet (Multi Input Multi Ouput)을 제시.
- MIMO-UNet은 다중 스케일 서브 네트워크를 쌓아 올리는 방식의 단점을 극복.
- 단일 네트워크에서 다중 스케일 입력과, 출력을 효율적으로 처리하는 방식을 제안한다.
- 이를 통해 Deblurring 문제에 성능, 효율성을 개선했다.
Introduction
- 초기 CNN을 기반으로 blur kernel을 추정하여 deconvolution으로 Deblurring을 수행.
- 이후 end-to-end 접근법으로 blur kernel을 추정하지 않고 CNN으로 직접 Deblurring을 수행.
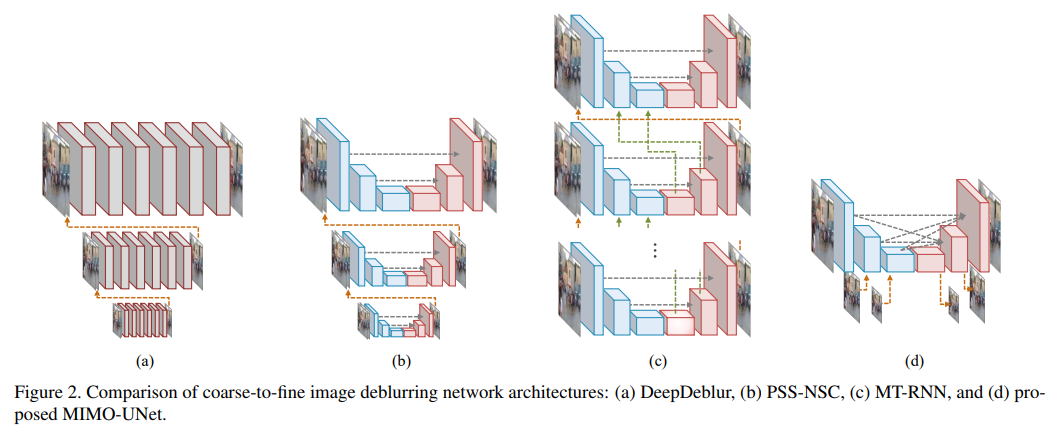
- DeepDeblur(a)는 end-to-end 접근 방법으로 coarse-to-find 방식으로 설계. 성능이 크게 향상되었다.
- 하지만 이러한 coarse-to-find 방식은 계산 복잡도와 메모리 사용량의 증가를 초래.
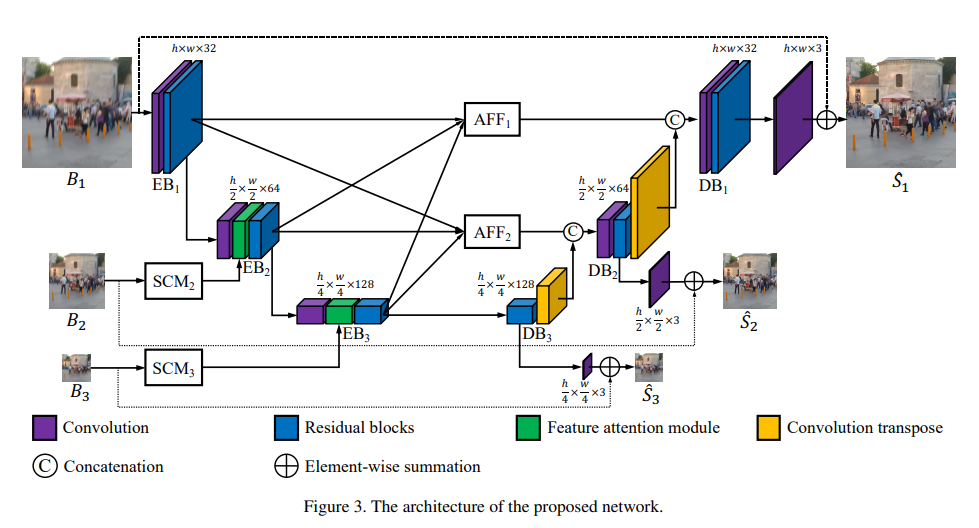
- MIMO-UNet은 coarse-to-fine 방식을 재검토. 아래와 같은 3가지 특징이 있다.
- MOSD (Multi Ouput Single Decoder)
- MIMO-UNet은 단일 디코더에서 여러 개의 디블러링된 Ouput을 출력
- MISE (Multi Input Single Encoder)
- MIMO-UNet의 단일 인코더는 다중 스케일 입력 이미지를 받는다.
- AFF (Asymmetric Feature Fusion)
- 비대칭 특징 융합을 도입하여 다중 스케일 특징들을 효율적으로 합친다.
- AFF는 서로 다른 스케일의 특징을 받아들여, 인코더와 디코더 간의 다중 스케일 정보 흐름을 합침.
- MOSD (Multi Ouput Single Decoder)
Proposed method
Multi-Input Single Encoder
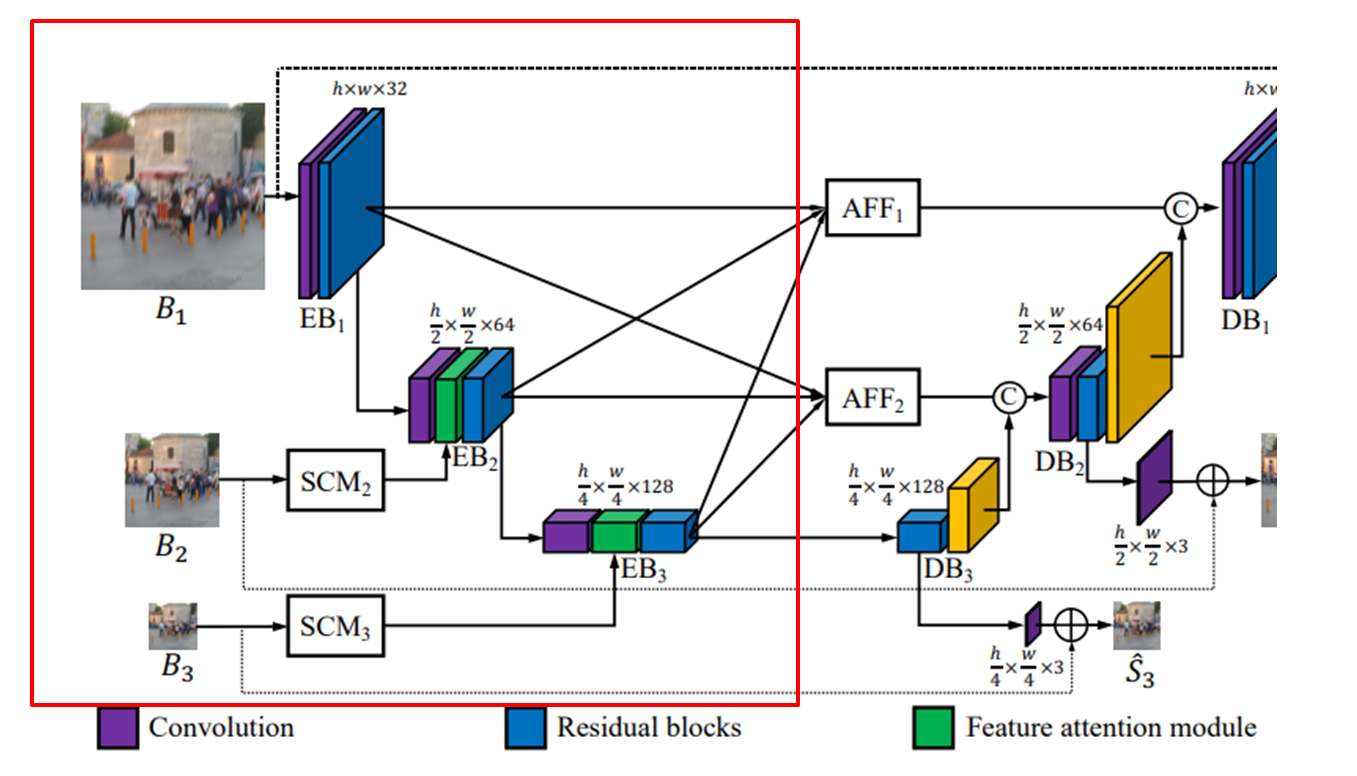
- 서로 다른 스케일의 블러 이미지를 입력으로 취함. 이로써 다양한 수준의 블러를 더욱 잘 처리할 수 있게 된다.
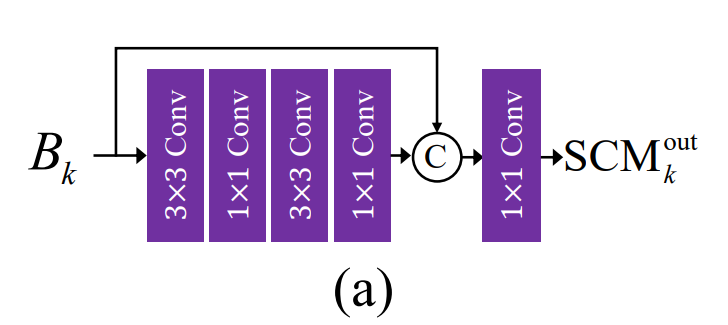
- 다운 샘플링된 이미지는 입력 시 Shallow Convolution Module(SCM)을 통해 feature를 추출, FAM에 전달.
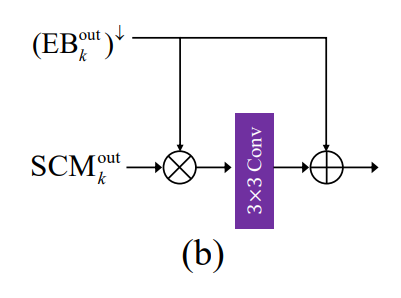
- FAM는 이전 스케일의 특징을 Attention 기법을 통해 강조하거나 억제하고, SCM의 특징을 학습한다.
- 이 모듈은 일반적인 융합 접근 방식보다 성능을 향상.
Multi-Output Single Decoder
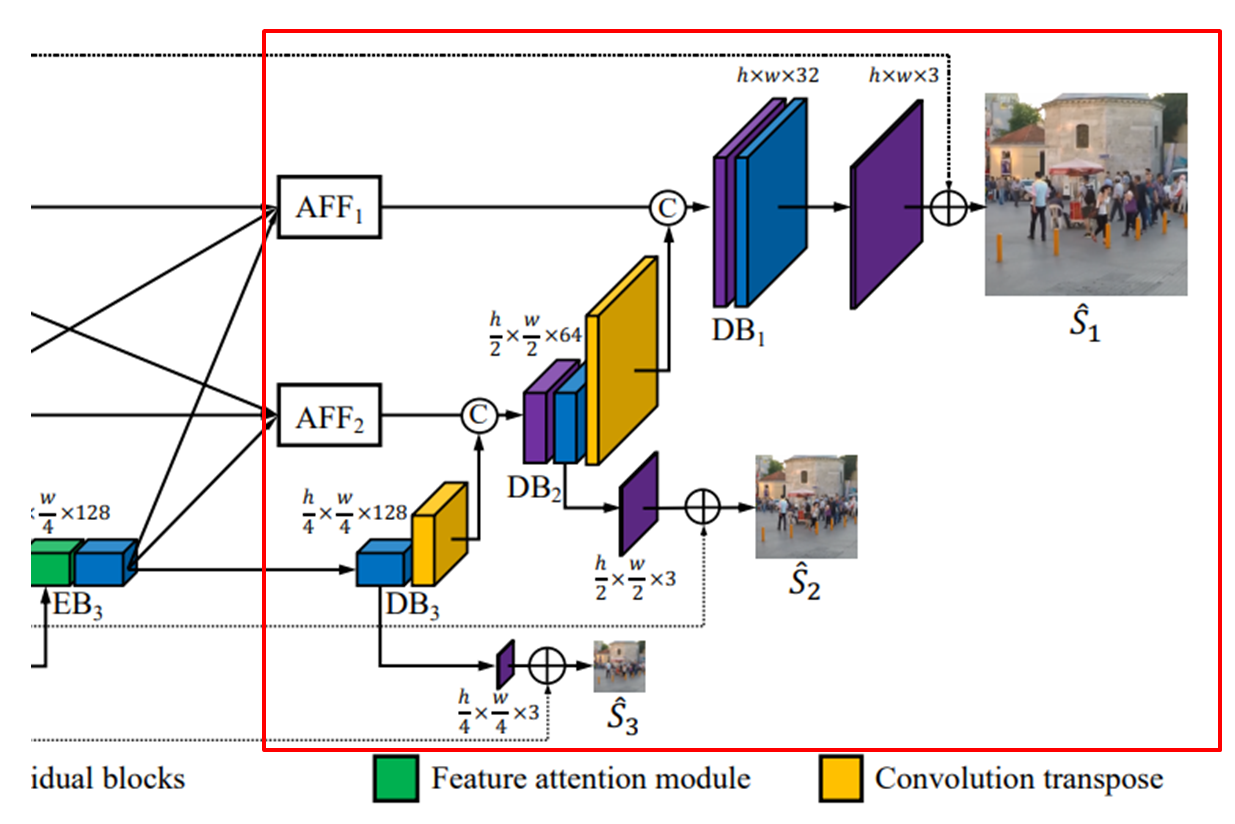
- 각 DB(Decoder Block)에서 다른 스케일의 특징 맵을 추출.
- 각 특징 맵은 단일 Convolution layer를 거쳐 이미지로 Deblurring 이미지로 출력된다.
Asymmetric Feature Fusion
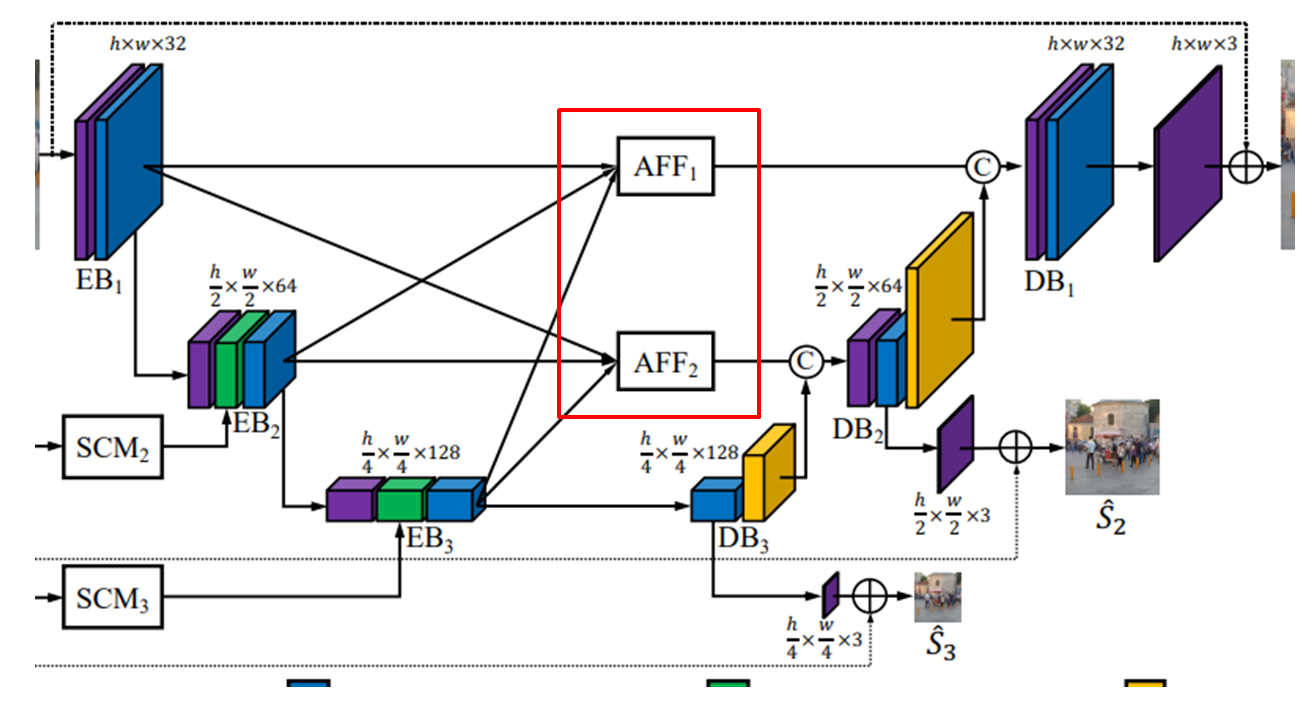
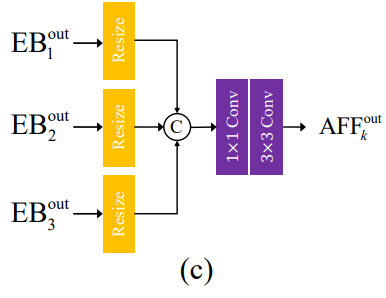
- AFF는 모든 스케일의 EB의 출력을 입력으로 받아 묶고, 이를 DB의 입력으로 전달한다.
- 서로 다른 스케일의 정보 흐름을 병합하는 역할.
- coarse-to-fine 구조와 같이 전체적인 특징과 세밀한 특징을 고려할 수 있는 장점이 있다.
Loss Function
- 다른 다중 스케일 디블러링 네트워크처럼 multi-scale content loss function을 사용.
- L1 loss가 MSE loss보다 더 나은 결과라는 것을 발견.
- content loss의 정의는 아래와 같다. (K는 level의 숫자. 정규화를 위해 loss를 총 element 수 t_k로 나눈다)
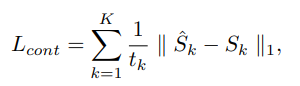
- 이미지 디블러링 성능 향상을 위한 보조 loss term으로 MSFR loss를 사용. (Multi-scale frequency reconstruction)
- 디블러링의 목적은 손실된 고주파 성분을 복원하는 것이므로, 주파수 공간에서의 차리를 줄이는 것이 중요하다.
- MSFR loss는 주파수 도메인에서 multi-scale의 실제 이미지와 디블러링된 이미지 간의 L1 거리를 측정.
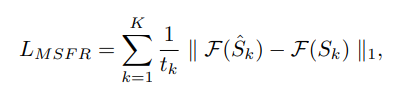
최종 loss function은 아래와 같다. (λ는 실험적으로 0.1로 set)
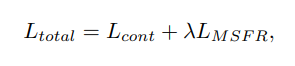
Experiments
성능 비교

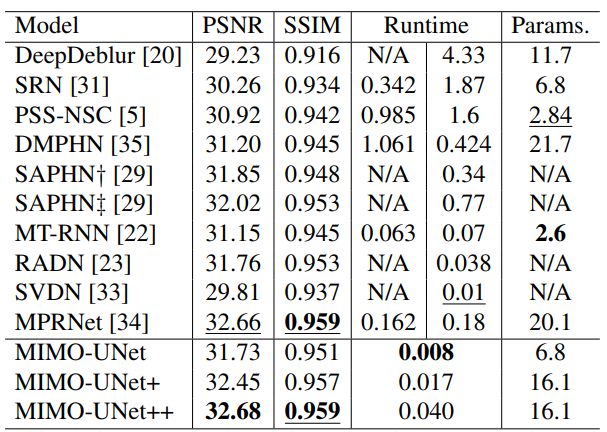
- 기존 디블러링 모델들과 비교.
- PSNR, SSIM 지표에서 성능 향상을 확인.
- 특히 처리 시간에서 좋은 성능을 보였다.
객체 감지 성능 향상

- 이미지 디블러링을 전처리로 사용했을 때 Object Detection task의 성능 향상을 확인.
반응형
'DeepLearning > Segmentation' 카테고리의 다른 글
| [Segmentation3D] PointNet (0) | 2021.01.25 |
|---|---|
| [Segmentation] SegNet (0) | 2021.01.08 |
| [Segmentation] U-Net (0) | 2021.01.08 |
| [Segmentation] FCN, Fully Convolutional Network (0) | 2021.01.07 |
반응형
Abstract
- 기존 coarse-to-fine 전략의 여러 서브 네트워크를 쌓아 다중 스케일 입력 이미지를 처리, 하위~상위 네트워크로 이미지 선명도를 점차 개선한다.
- 이러한 coarse-to-fine 전략은 높은 계산 비용을 초래.
- 본 논문은 MIMO-UNet (Multi Input Multi Ouput)을 제시.
- MIMO-UNet은 다중 스케일 서브 네트워크를 쌓아 올리는 방식의 단점을 극복.
- 단일 네트워크에서 다중 스케일 입력과, 출력을 효율적으로 처리하는 방식을 제안한다.
- 이를 통해 Deblurring 문제에 성능, 효율성을 개선했다.
Introduction
- 초기 CNN을 기반으로 blur kernel을 추정하여 deconvolution으로 Deblurring을 수행.
- 이후 end-to-end 접근법으로 blur kernel을 추정하지 않고 CNN으로 직접 Deblurring을 수행.
- DeepDeblur(a)는 end-to-end 접근 방법으로 coarse-to-find 방식으로 설계. 성능이 크게 향상되었다.
- 하지만 이러한 coarse-to-find 방식은 계산 복잡도와 메모리 사용량의 증가를 초래.
- MIMO-UNet은 coarse-to-fine 방식을 재검토. 아래와 같은 3가지 특징이 있다.
- MOSD (Multi Ouput Single Decoder)
- MIMO-UNet은 단일 디코더에서 여러 개의 디블러링된 Ouput을 출력
- MISE (Multi Input Single Encoder)
- MIMO-UNet의 단일 인코더는 다중 스케일 입력 이미지를 받는다.
- AFF (Asymmetric Feature Fusion)
- 비대칭 특징 융합을 도입하여 다중 스케일 특징들을 효율적으로 합친다.
- AFF는 서로 다른 스케일의 특징을 받아들여, 인코더와 디코더 간의 다중 스케일 정보 흐름을 합침.
- MOSD (Multi Ouput Single Decoder)
Proposed method
Multi-Input Single Encoder
- 서로 다른 스케일의 블러 이미지를 입력으로 취함. 이로써 다양한 수준의 블러를 더욱 잘 처리할 수 있게 된다.
- 다운 샘플링된 이미지는 입력 시 Shallow Convolution Module(SCM)을 통해 feature를 추출, FAM에 전달.
- FAM는 이전 스케일의 특징을 Attention 기법을 통해 강조하거나 억제하고, SCM의 특징을 학습한다.
- 이 모듈은 일반적인 융합 접근 방식보다 성능을 향상.
Multi-Output Single Decoder
- 각 DB(Decoder Block)에서 다른 스케일의 특징 맵을 추출.
- 각 특징 맵은 단일 Convolution layer를 거쳐 이미지로 Deblurring 이미지로 출력된다.
Asymmetric Feature Fusion
- AFF는 모든 스케일의 EB의 출력을 입력으로 받아 묶고, 이를 DB의 입력으로 전달한다.
- 서로 다른 스케일의 정보 흐름을 병합하는 역할.
- coarse-to-fine 구조와 같이 전체적인 특징과 세밀한 특징을 고려할 수 있는 장점이 있다.
Loss Function
- 다른 다중 스케일 디블러링 네트워크처럼 multi-scale content loss function을 사용.
- L1 loss가 MSE loss보다 더 나은 결과라는 것을 발견.
- content loss의 정의는 아래와 같다. (K는 level의 숫자. 정규화를 위해 loss를 총 element 수 t_k로 나눈다)
- 이미지 디블러링 성능 향상을 위한 보조 loss term으로 MSFR loss를 사용. (Multi-scale frequency reconstruction)
- 디블러링의 목적은 손실된 고주파 성분을 복원하는 것이므로, 주파수 공간에서의 차리를 줄이는 것이 중요하다.
- MSFR loss는 주파수 도메인에서 multi-scale의 실제 이미지와 디블러링된 이미지 간의 L1 거리를 측정.
최종 loss function은 아래와 같다. (λ는 실험적으로 0.1로 set)
Experiments
성능 비교
- 기존 디블러링 모델들과 비교.
- PSNR, SSIM 지표에서 성능 향상을 확인.
- 특히 처리 시간에서 좋은 성능을 보였다.
객체 감지 성능 향상
- 이미지 디블러링을 전처리로 사용했을 때 Object Detection task의 성능 향상을 확인.
반응형
'DeepLearning > Segmentation' 카테고리의 다른 글
| [Segmentation3D] PointNet (0) | 2021.01.25 |
|---|---|
| [Segmentation] SegNet (0) | 2021.01.08 |
| [Segmentation] U-Net (0) | 2021.01.08 |
| [Segmentation] FCN, Fully Convolutional Network (0) | 2021.01.07 |