SegNet
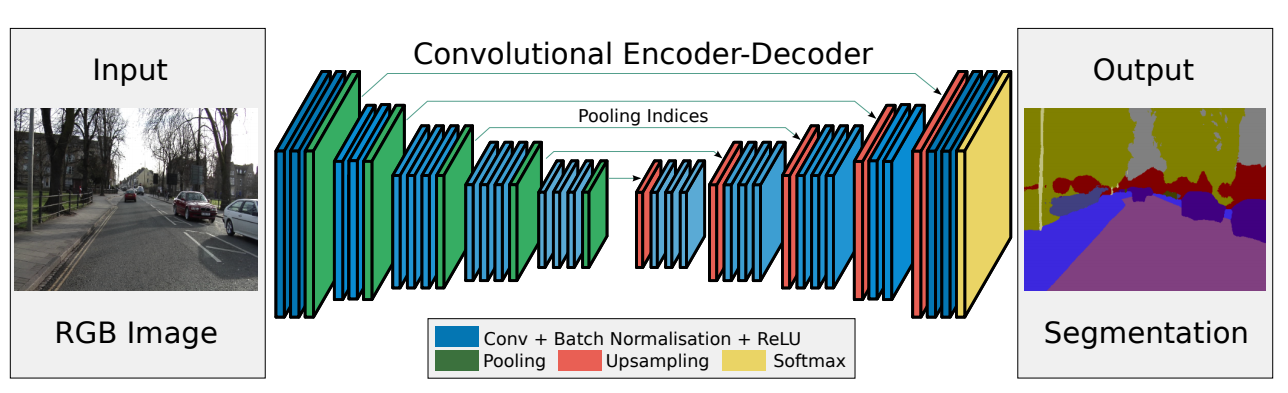
SegNet은 Encoder-Decoder 유형의 구조를 사용하는 Image Segmentation 모델이다. UNet과 마찬가지로 FCN의 구조를 이용했다고 볼 수 있다.
Encoder

SegNet 구조의 왼쪽 부분을 Encoder라 하며, Encoder에서는 VGG16의 13개 Convolution Layer을 동일하게 사용한다. Convolution, Pooling 구조들 통해 Input Image의 특징 맵(featrue map)을 추출하게 된다.
Decoder

오른쪽 부분을 Decoder라고 한다. Decoder에서는 Encoder에서 뽑은 특징 맵을 Upsampling과 Convolution을 하여 작아진 이미지를 원래 크기로 되돌린다.
Upsampling 후 마지막 Layer에서는 각 class의 픽셀 단위 분류를 위한 Softmax Layer가 존재.
FCN, U-Net과의 차이점
SegNet은 Encoder, Decoder 구조를 사용한다는 점에서 FCN, UNet과 매우 유사하다. (사실 U-Net, SegNet이 FCN 기반이기 때문에 당연...) 하지만 Max Pooling Indices라는 정보를 활용한다는 점에서 차이점이 있다.
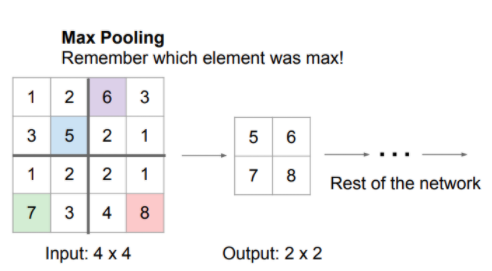
SegNet은 Encoding 할 때 pooling 과정에서 'Max-pooling Indices'라는 정보를 기억한다. (Max-pooling indices는 pooling 하기 전 data의 위치 정보라고 생각하면 된다.)

Decoding 할 때, Encoding 과정에서 저장한 Max-pooling indices를 이용하여 feature map을 upsampling.
FCN은 upsampling 할 때 Deconvolution을 학습해야 하기 때문에 그만큼 학습을 위한 가중치 파라미터가 필요하지만, SegNet에서는 이 과정이 생략되기 때문에 학습 파라미터가 줄게 된다.
U-Net 또한 Decoding과정에서 Skip combining을 하지만 UNet은 Encoder의 같은 층 feature map 전체 정보를 Decoder로 전달하여 concat.
때문에 Max pooling indices의 일부 특징만 골라 사용하는 SegNet보다 무겁다.
끝.
2021/01/07 - [DeepLearning/개념] - [Segmentation] FCN, Fully Convolutional Network
[Segmentation] FCN, Fully Convolutional Network
Segmentation? Segmentation이란 이미지상의 물체들을 픽셀 단위로 분할, 검출하는 것이다. Segmentation은 구체적으로 Sementic Segmentation과 Instance Segmentation으로 나뉜다. Sementic Segmentation은..
wjs7347.tistory.com
2021/01/08 - [DeepLearning/개념] - [Segmentation] U-Net
[Segmentation] U-Net
UNet UNet은 FCN(Fully Convolutional Network)을 수정하고 확장한 End-to-End 모델로, 모델 구조가 U 모양이라 U-Net이라 명칭 되었다. 2021/01/07 - [DeepLearning/개념] - [Segmentation] FCN, Fully Convol..
wjs7347.tistory.com
'DeepLearning > Segmentation' 카테고리의 다른 글
| [Deblurring] Rethinking Coarse-to-Fine Approach in Single Image Deblurring (MIMO-UNet) (0) | 2024.05.27 |
|---|---|
| [Segmentation3D] PointNet (0) | 2021.01.25 |
| [Segmentation] U-Net (0) | 2021.01.08 |
| [Segmentation] FCN, Fully Convolutional Network (0) | 2021.01.07 |